While at the airport reading “The Singularity is Near: 2045,” Ray Kurzweil persuaded me to code up a simple genetic algorithm (GA). The concept of GAs are pretty simply: start with a set of solutions and allow the best ones to survive and have offspring.
A simple application is in airline routing problems. Airlines have finite resources and must choose which flights to take in order to maximize their profits (airlines are an extreme example because of how low of margins they operate under).
In this post, we’ll walk through how to program a genetic algorithm in python to solve a linear maximization problem with linear constraints.
Solutions
We let a solution take the form 



#generates a 1D array (solution) of zeros and ones with probability p
#
#input: random 1d array with values in [0,1)
#output: converts values to 1 if element < p
def init_1D_p(x,p=0.5):
for i in range(len(x)):
if x[i] < p:
x[i] = 1
else:
x[i]=0
return x
#initializes k 1D solutions of length n
#
#output: row i is solution i
def init_solns_1D(k,n,p=0.5):
solns = np.zeros((k,n))
for i in range(k):
solns[i] = init_1D_p(np.random.rand(n),p)
return solns
Objective
In general, we will wish to either maximize or minimize some objective function that takes a solution as an input. We will assume that we wish to maximize (the assumption to maximize isn’t important since we can just maximze the negative of an objective function if we wanted the minimization) a linear function
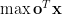
where 
#x: solutions with each row as a solution
#o: coefficients of objective function
def Linear_Objective(x):
o = np.array([1,2,3])
return np.dot(x,o)
Constraints
The solution will have to be feasible, meaning that it must satisfy some constraints.

We will deal with just one linear constraint
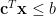
In our airline example, the coefficient of 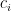


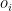
#x: solutions with each row as a solution
#c: coefficients so c_i is constraint coefficient for x_i
#ub: the upperbound
#
#return: boolean value; true if contraint satisfied
def Constraint1_UpperBound(x,c,ub):
return np.dot(x,c)<ub
Mating
An offspring, 


where 

#mates x1 and x2 and randomizes elements from child < p
def mate_1D(x1,x2):
rand_mate=np.random.rand(len(x1))
result= np.zeros(len(x1))
for i in range(len(x1)):
if rand_mate[i] < 0.5:
result[i] = x1[i]
else:
result[i] = x2[i]
return result
Mutations
After all evaluations have been made and offspring have replaced failed solutions, we introduce random mutations to each element of each member in the population.

We let each element of a solution mutate, or switch states, with probability 
#applies random mutations to elements of x with probability p
def random_mutation_1D(x,p=.01):
import random
rand_mate=np.random.rand(len(x))
for i in range(len(x)):
if rand_mate[i]<p:
x[i] = random.sample([0,1],1)[0]
return x
Process and Simulations
We can view implementing our genetic algorithm as a process, where the state of each element of our process is the 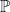
We will simulate a generation by evaluating each member of the population via the objective function and the constraints.
# return: booleans that are true if the index contains a working solution
def getWorkingSolutionIndices(constraint_results):
#results = np.array(sum(constraint_results))
results = []
for i in range(len(constraint_results)):
if constraint_results[i] == True:
results.append(i)
return np.array(results)
If the member does not satisfy all constraints, we will replace it by offspring of two members of the current generation that do satisfy the constraints; additionally, we will pick these members so that solutions that have a better objective measure have a greater probability of being chosen for mating. To do this, we create a probability mass function (pmf) where the probability of selecting a solution is proportional to how well it did on the objective function.
#returns a probability distribution with weighted values
#corresponding to objective solutions that satisfy constraints
def getPDF(solns,working_soln_ind,obj_results):
total = sum(obj_results[working_soln_ind])
prob = np.zeros(len(solns))
for i in working_soln_ind:
prob[i]=obj_results[i]/total
return prob
Now, to sample from this pmf we get the cumulative distribution function (cmf) and generate a uniform random variable.
#input:a probability mass function
#output: corresponding cdf
def getCDF(pmf):
cdf = np.zeros(len(pmf))
running_total = 0
for i,p in enumerate(pmf):
running_total += p
cdf[i] = running_total
return cdf
#samples pmf once and returns the index of the random sample
def sample_p_dist(pmf):
cdf = getCDF(pmf)
rand_num = random.random()
return np.argmax(cdf==cdf[np.argmax(cdf>rand_num)])
Since the big picture idea of applying a genetic algorithm is to find a good solution to our objective functions, we should store each feasible solution and its objective value.
def updateSolnToResult(solns,dictionary,objective_function,obj_coef):
for soln in solns:
dictionary[str(soln)]=objective_function(soln,obj_coef)
return dictionary
Now for simulating our algorithm we set some hyper-parameters and make sure to store the good results.
#reinitialize the solns
solnToResult={}
solns = init_solns_1D(num_solns,3)
#implementation that cares about satisfying constraint and maximizing our function
for _ in range(num_steps):
new_solns = np.zeros((num_solns,3))
obj_results = Linear_Objective(solns) #get objective value for each solution
c1_results = Constraint1_UpperBound(solns) #check constraints
#get working solution indices
working_soln_ind = getWorkingSolutionIndices(c1_results)
#get pmf of distribution to sample from
prob = getPDF(solns,working_soln_ind,obj_results)
#replace failed solutions with randmized ones
for i in range(num_solns):
if c1_results[i] == True:
updateSolnToResult(solns[i],solnToResult,Linear_Objective)
if(len(working_soln_ind)>=2): #check if mating is possible
#pick random solution to mate with according to the pmf from weighted obj results
mate_index=sample_p_dist(prob)
offspring = mate_1D(solns[i],solns[mate_index])
else:
offspring = solns[i]
else: #replace it with a some working solutions
if(len(working_soln_ind)<=2): #check if mating is possible
mate_index1,mate_index2 = sample_p_dist(prob),sample_p_dist(prob)
offspring = mate_1D(solns[mate_index1],solns[mate_index2])
else: #replace it with a some random solutions
offspring = init_1D_p(np.random.rand(3))
new_solns[i] = offspring
solns = mutate(new_solns) #reset the solution set and mutate
print solns
Conclusion
That’s all there is to it! This was a simple example, but if you need to program a genetic algorithm for more complicated problems, you should be able to follow this basic outline. To view a notebook with all the code, check out my github.
