Imagine that you have two images, and you want to create a new image based on some combination of the features of these images. What if you could use the style of one image and the content of the other to create this new image? For example, let’s say you have an image of the Hokusai’s The Great Wave of Kanagawa and a photo of the Seattle skyline, and you want to create a new picture that has the Seattle skyline painted in the pastel, oceanic, and foamy style of The Great Wave of Kanagawa.
The Great Wava of Kanagawa
Seattle Skyline
This task only seems possible via incredible artistic talent and obscure “vision.” But you can actually develop a systematic method to accomplish this.
The Great Wave of Kanagawa style
The Scream style
In fact, this process can be applied to any pair of style-content images to generate stellar results. The authors of A Neural Algorithm of Artistic Style figured out this process. This post will discuss how they did it.
Basic ideas
Computer vision
If you’ve never dealt with computer vision, it’s worth explaining how an image is represented in a computer. Let’s say your computer displays a black-and-white image. Your computer sees this image as nothing but a 2D map (this is not actually true, because those file extensions like jpeg and png are telling your computer the compression format, but just know that you can get this 2D map from your compressed image). You can think of this 2D map as a grid, where each element in the grid represents a pixel.
A pixel has an intensity that falls between 0 and 255, where 0 is not intense and 255 is super intense. In our black and white image, an intensity of 0 would be a black, 255 would be white, and anywhere in between would be grey.
A color image in your computer is nothing but three 2D maps, one for each primary color (red, green, and blue).
Each map represents the pixel intensities for one of those primary colors. For example, if you had an image that was pure red, you would expect only one of the maps to have non-zero pixels.
Mathematically, we can represent images similarly to how a computer would represent the images using tensors. For a gray-scale image, an image can be represented by a 2D tensor where is the pixel intensity of position of the grid. For a color image, an image can be represented by a 3D tensor where is the pixel intensity of position of the grid for color .
Convolutional neural networks
The most important tool for generating novel and stylish images is the convolutional neural network (CNN). To fully understand CNNs will take much more time than what this post allows, but luckily you don’t need to fully understand them to know how they’re used to generate art. A bit of history on how they came to be and a brief summary on how they operate should suffice.
CNNs are traditionally used in image object recognition tasks where images are fed into the CNN, and the CNN outputs a bunch of probabilities about what the main object is in the image (e.g. if you gave a CNN an image of a leopard, you would expect it output a how probability of a leopard).
In the case of image recognition, you can just think of CNN as a mathematical function that takes images as inputs and has probabilities as outputs. But in our case, we actually need to understand a bit more to be able to use them to generate new images.
CNNs achieve their object recognition expertise via transforming the input image through a series of layers, where each layer has a set of feature maps which represents certain features present in the image.
The authors learned that when you pass an image through a deep CNN (they used a modified version of VGG 19, which is a specific type of CNN) trained to perform well for image recognition (their network was trained on ImageNet), you could actually extract the image’s style and content from these feature maps.
A feature map can be represented in two ways: a 2D grid of values or a 1D vector of values. Intuitively, it make sense to think of a feature map as a 2D grid of values, because the feature map really is a 2D map of feature locations that correspond to the locations on the original image.
But if we are being pragmatic, we should be able to stretch out this 2D map into a long vector (1D tensor). This is actually how a lot of operations happen when convolutional networks are implemented.
We will be interested in referencing specific feature map values, so we define to be the value associated with location on feature map in layer .
Calculus with images
Before moving on to the details of the original paper, it’s important to recognize one more important tool that drives most of the results: using calculus to change images. Ultimately, if there is some function that describes the similarity or distance between two variables (and this function is differentiable), calculus can be used to describe how to change those variables so they are closer to each other. In our case, calculus can be used to change the values of pixels from an image until the image meets some criterion.
For example, let’s say we have two images: Vincent van Gogh’s The Starry Night and a white noise image–this is just an image that has pixel values sampled from a normal distribution that’s centered at 255/2 and truncated at 0 and 255.
The white noise image can be changed to look like The Starry Night by comparing each pixel of the two images, quantifying how much they differ, and then changing the white noise image accordingly.
The Starry Night
White noise image
The difference between two images and can be quantified by squaring the difference of pixel intensities between the two images for all pixels
This sum of errors is a loss quantifying the difference between two images. This loss is differentiable with respect to the pixels of the white noise image, and thus we can quantify how to change the pixel values in the white noise image to get the two images closer.
Once we change the white noise image to get a little closer to The Starry Night, we can again measure the loss and differentiate to find out what changes to make. This process can be repeated until the white noise image and The Starry Night image are indistinguishable.
Content reconstruction
In order to create new image using a blend of content and style, we first need a procedure/method that creates a new image which has content (i.e. the image scene) that matches the content of some other image; this method is known as content reconstruction. Reconstructing an image from its content can be done using CNNs, and it’s more straightforward than the reconstruction of style.
First, define a set of feature maps that will be used as criteria in content assessment. This is done by choosing a layer from the model. Next, get the values of these feature maps for a content image by passing the content image through the model; the feature maps at layer will be the target feature maps . Next, pass a white noise image through the model, and get the white noise feature maps . Then, compare the target feature maps with the white noise feature maps using a loss function similar to mean squared error
Differentiating this loss function with respect to the white noise image will yield derivatives of the loss with respect to pixels of the image. These derivatives can be used to change the white noise image so it has content closer to the content of the content image according to the feature maps in layer . After the changes to the white noise image have been made, the loss is measured again and changes are made to the white noise image. This is done until the white noise image has a scene that matches the scene of the content image. This procedure can be applied using a set of feature maps from any layer of the CNN.
conv1_1
conv2_1
conv3_1
conv4_1
conv5_1
Reconstructions that use earlier layers in the network preserve pixel details, whereas reconstructions with later layers lose details but preserve salient features (e.g. the reconstruction of an image that contained a house will still contain a house, but it might have something like a blurry window).
Style reconstruction
Reconstructing style of an image is less intuitive than reconstructing content, but it uses the same principles. Like content reconstruction, a set of feature maps is used as criteria in assessment (this time, style assessment) and is predefined. For each feature map inside the set of feature maps, the correlation of that feature map can be found with every feature map in the set. The unnormalized correlation of feature maps and is the dot product, which yields a scalar . A matrix of all feature map correlations for a collection of feature maps is called the Gram matrix
where is the number of feature maps in . It turns out that the original authors were experts at understanding how textures are represented in images. They knew that this Gram matrix would be a good way to define the texture/style of the image.
So, for each layer of a CNN, a Gram matrix can be computed that describes the style of an image. Because the authors were mathematicians, they figured that if we had two images we can get two Gram matrices, compare them with some sort of loss function, and then use calculus with the loss and pixels of one of the images to change that image to have style more like the other. Specifically the loss for a layer and style image would be
where is the weight of the loss for layer (this is a user specified parameter or can be retrieved from a user defined function by setting ), is the Gram matrix of the white noise image, is the Gram matrix of the style image, and is the size of a feature map from layer .
Style generation can be done using multiple layers of the network to take advantage of different aspects of style picked up by the CNN. To do this, we define a set of layers that we use to generate the style. Then we define our new style loss to be
The iterative process of changing a white noise image based off derivatives of a loss with respect to the pixels of the white noise image can be used with the style loss to create new images that have a style strikingly similar to the style image.
conv1_1
conv1_1 and conv 2_1
conv1_1, conv2_1, and conv3_1
conv1_1, conv2_1, conv3_1, and conv4_1
conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1
The authors figured out that a Gram matrix of an earlier layer in a network describes style at a smaller scale in the image while a Gram matrix of a later layer in the network describes style at a larger scale in the image.
Generating stylish images with content
Images that have the style of one image but the content of another can be generated by jointly changing a white noise image to satisfy style and content criteria simultaneously. To do this, we create a new loss
where is the layer used to reconstruct content, is the content weight, and is the style weight. Finally, we use this content-style loss as the criteria to change the white noise image.
The authors had a list of parameters specifying details like the layers used for creating style in the image. Here is that list:
ratio of content weight to style weight
.
The authors also used L-BFGS for optimization, but I found that Adam with a learning rate of about 1-5 can generate aesthetic results in roughly 500 to 2000 iterations.
Conclusions
Seemingly novel images can be generated that incorporate style from one image and content from another. This remarkable achievement uses convolutional neural networks to extract content and style from individual images while using clever loss functions and calculus to iteratively create new images. People have built upon the work of the original authors to create–again–astonishing computer generated images (Deep Dream and CycleGAN to name a few). The future of AI and its influence to our creative processes are very much in flux, and whatever comes next is sure to be extraordinary. Check out my GitHub for implementation of the full method and for code used to generate images in this post.
Most tutorial, deep learning blog posts that introduce recurrent neural networks (RNNs) use Long Short Term Memory (LSTM) cells in their examples. This happens because training vanilla recurrent neural networks is more difficult, and the results are less impressive. Still, it’s good to understand the basics of RNNs, because the area of sequential modeling is an active area of research with the incumbent state-of-the-art models knowing they won’t stay there for long. Just recently, researchers at Google used reinforcement learning to discover RNN architectures that beat LSTM cells.
Figure 0. An architecture that outperforms LSTM (image source)
I’ll walk through the architecture of simple recurrent neural networks (RNNs) and the corresponding code. For those just getting starting with neural nets for sequential modeling, a great intro to the applications and results of RNNs can be found here. If you want a thorough intro to RNNs, check out parts 1 and 2 of Danny Britz’s RNN posts. The goal of my post will be to share some of the idiosyncrasies that I learned while implementing basic RNNs. I will be using the most basic types of RNNs and won’t include LSTMs or GRUs. Additionally, I’ll explain and implement the two most common architectures of basic RNNs. The implementations will be done in Python using TensorFlow. As a data set I’ll use text8. The goal will be to do character sequence modeling; that is, given a sequence a characters, our model should provide a probability distribution over the characters in our alphabet for the next character in the sequence.
This was my first project having anything to do with natural language processing, and I found that most of my time was spent doing things like setting up batches of data, rather than building the neural networks. The next most time consuming element was understanding how to optimize the network through time. Hopefully this post will save you time or at least guide your experimentation as you begin your RNN journey.
RNN motivation
We want to be able to use previous information (i.e. the history of a sequence) to impact our decision at the current moment. Specifically, we want to be able to summarize the past and input that summary into the current state of our model.
Figure 1. States are transformed by f and used as input into the next state (figure from Deep Learning).
In neural nets, one way to do this would be to have a model that takes in our current input and the model’s state of the previous time-step. This is shown in Figure 2.
Figure 2. A neural network that takes in input x and the previous state h (figure take from Deep Learning).
Perhaps the most common use of RNNs is modeling text, and that’s what we’re doing in this post. Text is comprised of characters. Text is actually a sequence of characters, and thus should be modeled using something that has the capacity to understand the importance of the sequential relationships between the characters.
I’ll call the set of all characters that our model can understand an alphabet.
The goal of our model will be to provide a probability distribution over the alphabet for the next character in the sequence given what the model has already seen in the sequence.
RNN architectures
The most basic RNN is just a neural network with an extra input, where the extra input usually being the neural network’s hidden layer in the previous time-step (we’ll call this version Arch 1) or the neural network’s output in the previous time-step (we’ll call this version Arch 2). There are advantages to both of these, and they’re talked about in following subsections.
To simplify things further and illustrate the most basic RNN, we can think of an RNN as a system with inputs and outputs.
Figure 3. An RNN can be thought of as a system with an arbitrary numbers of inputs and outputs.
The system takes in inputs, usually some version of the state of the previous time-step of the RNN cell and the current sequence value (e.g. a character). Then the cell transforms the inputs by means of one or more neural nets and spits out outputs–usually a probability distribution of the next element in the sequence and the current state value. Throughout the post, it may be helpful to think of RNNs in this abstract way.
Arch 1
In Arch 1, our system has two inputs and two outputs. The current value of the sequence (e.g. a character) will be the first input and the model’s previous hidden layer will be the second input. The current output (i.e. the probability distribution of the letters in the alphabet for the next value in the sequence) will be the first output and the hidden layer of the RNN will be the second output (you can think of the hidden layer as the state of model). Figures 4 shows this model in the system view.
Figure 4. RNN with the extra input as the previous time-step’s hidden layer
To get a detailed view of what this architecture is actually doing, go to Figure 5.
Figure 5. Computation graph of RNN where the extra input is the hidden layer output of the previous time-step (figure taken from Deep Learning)
We see that the hidden layer of the previous time step is being transformed by and the current input is being transformed by . Both of these go into the hidden layer node, and thus there must be some operation that combines these two transformations. You can do this by concatenating, summing element-wise, multiplying element-wise, etc. In my implementations, I made sure that the dimensionality of equaled the dimensionality of so that element-wise operations were possible, but I found that concatenating yielded the best results (I do include a version of the implementation with element-wise addition in my Github); this make sense because the element-wise addition can be recovered from concatenation with a large enough matrix , but the linear combinations of both inputs cannot be recovered with element-wise operations.
The good thing about this architecture is that the hidden layer is being passed forward. This is nice because the hidden layer can be as large as we’d like and thus should be able to hold a sufficient summary of the history of a sequence that would allow the model to correctly predict the next sequence value.
Arch 2
In Arch 2, our model will have two inputs and one output. The input character will be one input and the model’s previous output will be the second input. The only output will be a probability distribution over the alphabet for the next sequence value. This model is nice, because it is simpler and will allow us to make a neat adjustment in training that should allow the model to train more efficiently. On the downside, the previous output alone won’t be able to provide a detailed history of the sequence, because given only the previous output and the current state, the model’s capacity is effectively reduced to a Markov chain whose state space is the alphabet. Figures 5 and 6 show the Arch 2 model.
Figure 5. RNN using the previous time-step’s output as the extra input.Figure 6. Computation graph of RNN where the extra input is the output of the previous time-step (figure take from Deep Learning)
With this model using only the previous output, you can use teacher forcing while training; this is just using the true/correct/target output for the second input instead of using the model’s output during training. Then, during test time you use the model’s output instead of the correct output. This is shown in Figure 7.
Figure 7. Teacher forcing is done during training by using the correct label as the extra input. During test time the model’s output is used as the extra input. (figure taken from Deep Learning)
I suppose that if you knew the correct previous output during test time, you’d use that instead of the model’s output. These models are usually used to generate sequences, which is probably why the authors of Deep Learning said to use the model’s output during test time.
We will implement both models in this post, but we’ll focus on Arch 1, because it has greater modeling capacity.
RNN tragedies
I won’t talk about the main issues with vanilla RNNs here, because they’re extensively mentioned in almost every other resource. But if you are completely new to RNNs, know that they are infamous for having trouble learning due to gradients that both vanish and explode.
Unfortunately, I found that both of the implementations of RNNs are finicky. It took a lot of time to find a way to train the models that actually gave intended results. The most important decision was the choice of a loss function. It turns out that not using the log-likelihood really messes up the training.
Figure 8. A reminder to use the negative log likelihood as a loss function.
So make sure to use standard cross-entropy or your own implementation of the negative log-likelihood loss function while training.
Another big issue was finding a learning rate. You should feel free to experiment with these networks, but you might find it less frustrating to start with the parameters I provide, because finding a combination that trains well is non-trivial.
It’s not surprising that there were difficulties, because that’s what most other people who are proficient in these networks say (and one of the reasons LSTMs are so amazing). Conversely, if you use a gating structure, such as what’s in an LSTM cell, the results are amazing and most of the difficulties go away. I have yet to explore other gating structures, and that might be a topic of a future post (for example, different types of Long Short Term Memory (LSTM) cells, like what Christopher Olah describes here, or Gated Recurrent Units (GRUs)).
Data
We’ll use the text8 dataset, which is a lot of cleaned up text that was scraped from about 100,000 wikipedia pages. The text will only contain lowercase letters “a” through “z”. The data can be downloaded with the following function, which I found from Udacity’s Deep Learning course.
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
"""Download a file if not present, and make sure it's the right size."""
if not os.path.exists(filename):
filename, _ = urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified %s' % filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
Then this function can be used to read the data into memory.
def read_data(filename):
f = zipfile.ZipFile(filename)
for name in f.namelist():
return tf.compat.as_str(f.read(name))
f.close()
text = read_data(filename)
print('Data size %d' % len(text))
The text variable should be one string that’s 10 million characters long.
Alphabet
I like to create a globally defined alphabet, so we know exactly what characters we’re modeling. This gives us flexibility later on if we should to include more characters. Of course, with the current data this won’t be possible, because we are using a cleaned version of text that only includes lowercase English letters “a” through”z” and the space character.
alphabet = ' '+string.ascii_lowercase
global alphabet
alphabet_size = len(alphabet)
Next up is to write some helper functions for dealing with our data. Our model will required numerical versions of characters. First, let’s create a one-to-one mapping from characters to integers.
#character to int
def char2id(x):
if x in alphabet:
return alphabet.find(x)
else:
return 0
#id to char
def id2char(x):
return alphabet[x]
Second, the integers will need to be one-hot encoded so they can be fed into the model.
#letter to one_hot encoded vector
def char2vec(x):
r = np.zeros([alphabet_size],dtype=np.int8)
r[char2id(x)] = 1.0
return r
Lastly, it’ll also be useful to have a function that takes in a one-hot encoded vector and transforms it into a 2D array, because we’ll be doing matrix multiplication with the vector.
#turn the one-hot vector into a matrix
def vec2mat(x):
return np.reshape(x,(1,len(x)))
Probability distributions
If we are using our model to generate sequences, and we have a probability distribution over the elements of our alphabet, we will need to sample from this distribution to choose the next element in our sequence.
def sample_prob(prob):
r=random.random()
s=0
for i,p in enumerate(prob):
s+=p
if s>=r:
return i
return 'Awry sampling probs'
Additionally, it’ll be good to have a function that creates a random distribution over our alphabet for when we initialize our model during sequence generation.
#random distribution
def random_dist():
r = np.random.rand(alphabet_size)
return r/np.sum(r)
Unrollings
In order to compute gradients with respect to previous values of the sequence and their respective transformations, the entire sequence up to the point you wish to differentiate with respect to will need to be inputted during the training step: the implementation of this concept is known as unrolling the network.
Figure 9. An illustration of t unrollings of an RNN (image taken from Chris Olah’s blog).
To understand the importance of unrollings during training, let’s think about the following example. Suppose our network has zero unrollings during training. That is, during each training step, the network is only given the current input of the sequence and some previous information about the history of the sequence; in Arch 1 the previous information would be the RNN’s previous hidden state while in Arch 2 the previous information would either be the model’s previous output or the previous correct target if teacher forcing is used.
Figure 11. An RNN with zero unrollings
Then, the network is the supposed to output the next value of the sequence, and its output is compared to the target via the loss function. If the current target is highly dependent not on the current value of the sequence but on the previous values of the sequence, the network will only be able to change how the information of the previous values of the sequence that is inputted into the current state of the model is transformed, but not how the information of the previous values is represented. In Figure 11. the network can change how the weight matrix transforms its inputs, but it can’t transform the inputs.
Thus, there is an incentive to increase the number of unrollings during training. Unfortunately, as the number of unrollings increases, the gradients used to train the network will either explode or vanish exponentially. The good news is that to keep them from exploding, you can simply pick a ceiling to cap the gradients; this is known as gradient clipping. The bad news is that to keep the gradients from vanishing, you have to use some type of gated RNN (e.g. LSTM), use leaky units, or remove connections; because this post is focusing on vanilla RNNs, we won’t use these and will have to choose a small value for our number of unrollings .
Batches
Generating batches for sequential text models seems strange at first for a few reasons. The main reason is that the like a typical classification problem the model will output a class label (except in this case the goal is to correctly classify the next value in a sequence), but unlike most classification problems the class label will be used both as a model input and a target (the target of the current time-step will be the input at the next time-step). The other reason generating batches seems odd is because the inputs and targets for the entire unrolling need to be generated and inputted into the modeling before computing the loss.
I like to think of one batch of inputs–that is, a matrix with one-hot encoded vectors as rows–as part of a mega batch. The reason for this mega batch has to do with the unrollings that happens in training. You’ll need to feed a batch of inputs for each unrolling during each step of training. There are plenty of ways to do this, but I just created a mega batch for each step of training, where each element of the mega batch is a batch.
class Batch(object):
def __init__(self,text,batch_size):
self.text = text
self.text_size = len(text)
self.batch_size = batch_size
self.segment_size = self.text_size//batch_size
self.cursors = [self.segment_size*b for b in range(batch_size)]
def next(self):
self.cursors = [(c + 1) % self.text_size for c in self.cursors]
x,y = [self.text[c] for c in self.cursors], [self.text[(c+1)%self.text_size] for c in self.cursors]
return x,y
The goal is to predict the next character, so that’s why the labels are just the next character.
There will be batch size many cursors, each keeping track of the index of a sequence of characters. Figure 12 shows the cursors for the first batch, Figure 13 shows the cursors for the second batch, and Figure 14 shows the cursors for the eighth batch.
Figure 12. The data is represented by a long string and each cursor holds the location of a character. The current locations of the cursors is for the first batch.Figure 13. Cursor locations for the second batch.Figure 14. Cursor location for the eighth batch.
We’ll create another function that takes in a Batch object and spits out inputs and labels
def getWindowBatch(b,num_unrollings):
window_batch = []
for i in range(num_unrollings):
window_batch.append(b.next())
window_batch=zip(*window_batch)
x,y = list(window_batch[0]),list(window_batch[1])
return x,y
Maybe you noticed that the class doesn’t actually create a mega batch, and you’re correct. We create a mega batch for the input characters and labels the same way: by indexing through the unrollings and batch size.
#trains x
mega_batch_x = [] #each elemnt will be a batch. there will be n elements where n is the number of unrollings
for n in range(num_unrollings):
batch = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
for ba in range(batch_size):
batch[ba]=char2vec(batch_x[n][ba])
mega_batch_x.append(batch)
Hyperparameters and initial conditions
Training these networks is the toughest part. You’ll have to take special care creating batches, saving/passing variables, picking parameters, and computing gradients.
Let’s say we have a batch size of . We need to pick, ahead of time, a value which will be the number of unrollings of time-steps in our graph during training. It can be helpful to think of as the number of inputs we feed into our model before computing the loss and updating parameters. I found that the max number of unrollings you can use before having major training issues with vanishing gradients is 20. However, I was able to get the unrollings up to 40 by using a ReLU instead of hyperbolic tangent for an activation function.
We will one-hot encode the characters so each mega batch will have matrices of size x alphabet_size.
You might be wondering what to use as the initial input, because if we haven’t run our model we won’t have a previous output or hidden layer to pass into the current model. I couldn’t find a standard for this, so I just initialized the extra input as a vector of all zeros.
I set the learning rate to do an exponential decay, mostly because the learning rate has a huge impact on training performance, and the decay allowed me to see which ranges were behaving the best. In general, I found that a learning rate of in the range of 0.1 and 2.5 is where most of the learning happens.
Implementations in TensorFlow
Both architectures are tricky to get working in TensorFlow. Before training, the entire graph will need to be defined, which means that placeholders need to be defined for inputs and target values of each unrolling. Normally, we would define a placeholder on a graph using something like this
a = tf.placeholder(tf.float32,shape=(batch_size,alphabet_size))
where we define a Python variable for the placeholder. If we want to experiment with the number of unrollings, we would have to manually add or removes lines of code. Luckily, the placeholders can be elements of a list, which means that they don’t need to be explicitly typed out in the script. So we can use a graph definition like this.
train = list()
for i in range(num_unrollings):
train.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size))
Then to feed the values into the placeholder, we can reference the list that stores them on the graph (in this case it’s our train variable). This allows us to iteratively add keys to the feed dictionary with something like this.
feed_dict = {}
for i in range(num_unrollings):
feed_dict[train[i]] = x[i]
The rest of the implementation techniques are normal. The full implementations for both architectures are shown in the following sections.
Implementing Arch 1
We build the graph that defines the computations which are shown in Figure 5.
batch_size=32
num_nodes = 100
num_unrollings = 40
g = tf.Graph()
with g.as_default():
#input fed into the cell, could be a batch of training data or a single one-hot encoded vector
train = list()
for i in range(num_unrollings):
train.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#the previous hidden layer gets fed into the cell
output_feed= tf.placeholder(tf.float32,shape=(batch_size,2*num_nodes),name='one')
#one-hot encoded labels for training
labels = list()
for i in range(num_unrollings):
labels.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#validation place holder
val_input = tf.placeholder(tf.float32,shape=(1,alphabet_size))
val_output = tf.placeholder(tf.float32,shape=(1,2*num_nodes))
#Variables
#input matrix
U = tf.Variable(tf.truncated_normal([alphabet_size,num_nodes],-0.1,0.1))
#recurrent matrix multiplies previous hidden layer
W = tf.Variable(tf.truncated_normal([2*num_nodes,num_nodes],-0.1,0.1))
#bias vector
b = tf.Variable(tf.zeros([1,2*num_nodes]))
#output matrix
V = tf.Variable(tf.truncated_normal([2*num_nodes,alphabet_size],-0.1,0.1))
c = tf.Variable(tf.zeros([1,alphabet_size]))
#model
def RNN(i,h_input):
a = tf.concat(1,[tf.matmul(i,U),tf.matmul(h_input,W)])+b
h_output = tf.nn.relu(a)
o_out = tf.matmul(h_output,V)+c
return h_output,o_out
#when training truncate the gradients aftern num_unrollings
for i in range(num_unrollings):
if i == 0:
outputs = list()
hidden_after,output_after = RNN(train[i],output_feed)
else:
hidden_after,output_after = RNN(train[i],hidden)
hidden = hidden_after
outputs.append(output_after)
#train
#log likelihood loss
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(tf.concat(0,outputs),tf.concat(0,labels)))
#optimizer
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
learning_rate=2.5,global_step=global_step, decay_steps=80000, decay_rate=0.75, staircase=True)
optimizer = tf.train.AdadeltaOptimizer(learning_rate=learning_rate)
gradients,var=zip(*optimizer.compute_gradients(loss))
gradients_clipped, _ = tf.clip_by_global_norm(gradients, 1.25)
opt=optimizer.apply_gradients(zip(gradients_clipped,var),global_step=global_step)
# Validation
val_hidden_after,val_output_after = RNN(val_input,val_output) #change train to input_in
val_probs = tf.nn.softmax(val_output_after)
#add init op to the graph
init = tf.initialize_all_variables()
Next, we create a TensorFlow session with our graph, train, and evaluate periodically through training.
num_steps=800001
b = Batch(text,batch_size)
sess=tf.Session(graph=g)
sess.run(init)
average_loss = 0
for step in tqdm(range(num_steps)):
#get the new inputs and labels
batch_x,batch_y=getWindowBatch(b,num_unrollings)
if (step*b.batch_size)%(b.text_size) < b.batch_size:
print " "
print "NEW EPOCH"
print " "
#initialize the output
if step == 0: #initialize the output state vectors
output_pass = np.zeros([batch_size,2*num_nodes],dtype=np.float32)
feed_dict={output_feed: output_pass}
#trains x
mega_batch_x = [] #each elemnt will be a batch. there will be n elements where n is the number of unrollings
for n in range(num_unrollings):
batch = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
for ba in range(batch_size):
batch[ba]=char2vec(batch_x[n][ba])
mega_batch_x.append(batch)
for i in range(num_unrollings):
feed_dict[train[i]] = mega_batch_x[i]
#trains y
mega_batch_y = [] #each elemnt will be a batch. there will be n elements where n is the number of unrollings
for n in range(num_unrollings):
batch = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
for ba in range(batch_size):
batch[ba]=char2vec(batch_y[n][ba])
mega_batch_y.append(batch)
for i in range(num_unrollings):
feed_dict[labels[i]] = mega_batch_y[i]
output_pass,l,_=sess.run([hidden_after,loss,opt],feed_dict=feed_dict)
average_loss += l
if step % 1000 == 0:
print 'Average loss: ',str(average_loss/1000)
average_loss = 0
print 'Learning rate: ', str(learning_rate.eval(session=sess))
#sample and then generate text
s=''
#initialize the validations out, state, and character
val_output_O = np.zeros(2*num_nodes).reshape(1,2*num_nodes)
char_id = sample_prob(random_dist()) #create a random distribution then sample
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
for _ in range(100):
feed_dict = {val_input: val_input_O,
val_output: val_output_O}
val_output_O,dist = sess.run([val_hidden_after,val_probs],feed_dict=feed_dict)
char_id=sample_prob(dist[0])
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
print s
Implementing Arch 2 with teacher forcing
We build the graph defining the computations which are shown in Figure 7.
batch_size = 64
num_nodes = 50
num_unrollings = 20
g = tf.Graph()
with g.as_default():
#input fed into the cell, could be a batch of training data or a single one-hot encoded vector
train = list()
for i in range(num_unrollings):
train.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#the previous output the gets fed into the cell
output_feed= tf.placeholder(tf.float32,shape=(batch_size,alphabet_size),name='one')
#one-hot encoded labels for training
labels = list()
for i in range(num_unrollings):
labels.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#validation place holder
val_input = tf.placeholder(tf.float32,shape=(1,alphabet_size))
val_output = tf.placeholder(tf.float32,shape=(1,alphabet_size))
#Variables
#input matrix
U = tf.Variable(tf.truncated_normal([alphabet_size,num_nodes],-0.1,0.1))
#recurrent matrix multiplies previous output
W = tf.Variable(tf.truncated_normal([alphabet_size,num_nodes],-0.1,0.1))
#bias vector
b = tf.Variable(tf.zeros([1,2*num_nodes]))
#output matrix
V = tf.Variable(tf.truncated_normal([2*num_nodes,alphabet_size],-0.1,0.1))
c = tf.Variable(tf.zeros([1,alphabet_size]))
#model
def RNN(i,o_input):
a = tf.concat(1,[tf.matmul(i,U),tf.matmul(o_input,W)])+b
h_output = tf.nn.tanh(a)
o_out = tf.matmul(h_output,V)+c
return o_out
#when training truncate the gradients after num_unrollings
for i in range(num_unrollings):
if i == 0:
outputs = list()
output_after = RNN(train[i],output_feed)
else:
output_after = RNN(train[i],labels[i-1])
outputs.append(output_after)
#train
#log likelihood loss
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(tf.concat(0,outputs),tf.concat(0,labels)))
#optimizer
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
learning_rate=2.5,global_step=global_step, decay_steps=5000, decay_rate=0.1, staircase=True)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
gradients,var=zip(*optimizer.compute_gradients(loss))
gradients_clipped, _ = tf.clip_by_global_norm(gradients, 1.25)
opt=optimizer.apply_gradients(zip(gradients_clipped,var),global_step=global_step)
# Validation
val_output_after = tf.nn.softmax(RNN(val_input,val_output))
val_probs = tf.nn.softmax(val_output_after)
#add init op to the graph
init = tf.initialize_all_variables()
Then, we go through the training and validation.
num_steps=50001
b = Batch(text,batch_size)
sess=tf.Session(graph=g)
sess.run(init)
average_loss = 0
for step in range(num_steps):
if (step*b.batch_size)%(b.text_size) < b.batch_size:
print " "
print "NEW EPOCH"
print " "
#initialize the output
if step == 0: #initialize the output state vectors
output_pass = np.zeros([batch_size,alphabet_size],dtype=np.float32)
feed_dict={output_feed: output_pass}
#get the new inputs and labels
batch_x,batch_y=getWindowBatch(b,num_unrollings)
#mega batches
mega_batch_x = [] #each elemnt will be a batch. there will be tau elements where tau is the number of unrollings
mega_batch_y = []
for n in range(num_unrollings):
batchx = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
batchy = np.ndarray((batch_size,alphabet_size))
for ba in range(batch_size):
batchx[ba]=char2vec(batch_x[n][ba])
batchy[ba]=char2vec(batch_y[n][ba])
mega_batch_x.append(batch)
mega_batch_y.append(batch)
for i in range(num_unrollings):
feed_dict[train[i]] = mega_batch_x[i]
feed_dict[labels[i]] = mega_batch_y[i]
output_pass,l,_=sess.run([output_after,loss,opt],feed_dict=feed_dict)
average_loss += l
if step % 1000 == 0:
print 'Average loss: ',str(average_loss/1000)
average_loss = 0
print 'Learning rate: ', str(learning_rate.eval(session=sess))
#sample and then generate text
s=''
#initialize the validations out and character
val_output_O = vec2mat(char2vec(id2char(sample_prob(random_dist()))))
char_id = sample_prob(random_dist()) #create a random distribution then sample
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
for _ in range(100):
feed_dict = {val_input: val_input_O,
val_output: val_output_O}
val_output_O,dist = sess.run([val_output_after,val_probs],feed_dict=feed_dict)
char_id=sample_prob(dist[0])
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
print s
Results
The following sequences of text were generated from Arch 1 and Arch 2.
Arch 1
wide chromber coorers are stare printiun s cont imegres and somporad stodarimestudidgo ymare matiscqpmhcytkaip
han ar engune comely occupler incensit one five three cimmplied s blogmon if at zero nendenc
mulices other jounilis indreased bistroniparen e ghreg the promisem both amorg nizenir
That wraps up what I’ve learned about plain vanilla RNNs. You can find all my code in this Github repo. This post should demystify a lot of the magic (perhaps even reveal some of the ugliness) of RNNs. Clearly, the results weren’t the best, and I’d encourage anyone to give LSTMs a try, because their results are alarmingly impressive.
Sequential modeling is an active research area, and all types of RNNs are being researched for understanding and practicality. Hopefully, you’ll be able to springboard off this work and create, discover, or tweak your own RNN!
Recently, I ran into some computational limits on my laptop while doing training some CNNs. I have a desktop, but given a tough enough problem, even it won’t suffice. Thus, the cloud is eventually going to be the only available option. Unfortunately, the cloud is so far away that I still can’t find it despite everyone talking about it, so how would we ever find the notebook?… Seriously though, most cloud operating systems don’t come installed with a desktop environment (think Ubuntu server). But let’s say you go ahead and install a desktop environment or start off with Ubuntu desktop. You’ll have to use X11 to send all your browser information through ssh, which can be slow; additionally, you’ll need to configure Xorg on the server. I’ll show you an easier solution that uses ssh tunneling and only requires ssh and jupyter notebook to be installed on your cloud instance. This post uses an EC2 instance from Amazon running Ubuntu server, but the method should work for any remote linux machine with ssh installed.
Jupyter Notebook in the cloud is one ssh tunnel away from your local machine.
0. Launch a cloud instance and install the appropriate software
Launch an AWS EC2 instance or find some remote linux machine if you don’t already have one. I already launched an AWS EC2 instance and generated my key named “EC2Test.pem” which I left at ~/Desktop. So anytime you see ~/Desktop/EC2Test.pem just replaces it with /.pem. Additionally, I installed anaconda which comes with jupyter notebook, so make sure you’ve got the notebook in the cloud. Throughout this post make sure to use whatever ssh convention is necessary to properly ssh into your machine. I was running Ubuntu at ec2-35-161-33-142.us-west-2.compute.amazonaws.com , so if you’re also running Ubuntu in AWS just replace the address . Finally, make sure to add your IP address to your security group to save you a headache…
1. Open jupyter properly
ssh into your machine by opening a new terminal and entering
-N tells ssh that a remote command won’t be sent; it doesn’t attempt to log you into the server
-f allows the tunnel to be forked into the background so you can close the terminal. If you use this option, you’ll have to kill the tunnel manually by finding the process. I usually leave out this option
-L tells ssh that you are going to pass in the local and remote addresses
localhost:8888 is the address on your local machine that you are forwarding to
localhost:8886 is the address on your cloud instance that jupyter is forwarding to which is the same address that you specified when opening jupyter
3. Use your notebook
On your local machine, open a browser and go to localhost:8888. Viola! You should see your Jupyter Notebook.
If you’re up to date with the AI world, you know that Google recently released a model called Inception v3 with Tensorflow.
Figure 0. Inception v3 model comes with Tensorflow (image source)
You can use this model by retraining the last layer per your classification requirements. If you’re interested in doing this, check out this speedy 5 min tutorial by Siraj Raval. The namesake of Inception v3 is the Inception modules it uses, which are basically mini models inside the bigger model. The same Inception architecture was used in the GoogLeNet model which was a state of the art image recognition net in 2014.
Figure 1. GoogLeNet architecture with nine inception modules (image source)
In this post we’ll actually go into how to program Inception modules using Tensorflow following the details described by the original paper, “Going Deep with Convolutions.” If you’re not already comfortable with convolutional networks, check out Chapter 9 of the Deep Learning book, because we’ll assume that you already have a good understanding of convolutional operations and that you’ve coded some simpler convnets in Tensorflow.
What are Inception modules?
As is often the case with technical creations, if we can understand the problem that led to the creation, we will more easily understand the inner workings of that creation.
Believe it or not, Inception modules partially got their name from this meme (image source)
Udacity’s Deep Learning Course did a good job introducing the problem and the main advantages of using Inception architecture, so I’ll try to restate them here. The inspiration comes from the idea that you need to make a decision as to what type of convolution you want to make at each layer: Do you want a 3×3? Or a 5×5? And this can go on for a while.
Figure 2. Udacity video explaining the motivation behind Inception (image source)
So why not use all of them and let the model decide? You do this by doing each convolution in parallel and concatenating the resulting feature maps before going to the next layer.
Now let’s say the next layer is also an Inception module. Then each of the convolution’s feature maps will be passes through the mixture of convolutions of the current layer. The idea is that you don’t need to know ahead of time if it was better to do, for example, a 3×3 then a 5×5. Instead, just do all the convolutions and let the model pick what’s best. Additionally, this architecture allows the model to recover both local feature via smaller convolutions and high abstracted features with larger convolutions.
Architecture
Now that we get the basic idea, let’s look into the specific architecture that we’ll implement. Figure 3 shows the architecture of a single inception module.
Figure 3. Inception module from “Going Deeper with Convolutions.” (image source)
Notice that we get the variety of convolutions that we want; specifically, we will be using 1×1, 3×3, and 5×5 convolutions along with a 3×3 max pooling. If you’re wondering what the max pooling is doing there with all the other convolutions, we’ve got an answer: pooling is added to the Inception module for no other reason than, historically, good networks having pooling. The larger convolutions are more computationally expensive, so the paper suggests first doing a 1×1 convolution reducing the dimensionality of its feature map, passing the resulting feature map through a relu, and then doing the larger convolution (in this case, 5×5 or 3×3). The 1×1 convolution is key because it will be used to reduce the dimensionality of its feature map. This is explained in detail in the next section.
Dimensionality reduction
This was the coolest part of the paper. The authors say that you can use 1×1 convolutions to reduce the dimensionality of your input to large convolutions, thus keeping your computations reasonable. To understand what they are talking about, let’s first see why we are in some computational trouble without the reductions.
Let’s say we use, we the authors call, the naive implementation of an Inception module.
Figure 4 shows an Inception module that’s similar to the one in Figure 3, but it doesn’t have the additional 1×1 convolutional layers before the large convolutions (3×3 and 5×5 convolutions are considered large).
Let’s examine the number of computations required of the first Inception module of GoogLeNet. The architecture for this model is tabulated in Figure 5.
Figure 5. GoogLeNet architecture with the previous layer dimensions and the Inception module of interest highlighted in green and red, respectively
We can tell that the net uses same padding for the convolutions inside the module, because the input and output are both 28×28. Let’s just examine what the 5×5 convolution would be computationally if we didn’t do the dimensionality reduction. Figure 6. pictorially shows these operations.
Figure 6. 5×5 convolutions inside the Inception module using the naive model
There would be
Wow. That’s a lot of computing! You can see why people might want to do something to bring this number down.
To do this, we will ditch the naive model shown in Figure 4 and use the model from Figure 3. For our 5×5 convolution, we put the previous layer through a 1×1 convolution that outputs a 16 28×28 feature maps (we know there are 16 from the #5×5 reduce column in Figure 5), then we do the 5×5 convolutions on those feature maps which outputs 32 28×28 feature maps.
Figure 7. 1×1 convolutions serve as the dimensionality reducers that limit the number of expensive 5×5 convolutions that follow
In this case, there would be
Although this is a still a pretty big number, we shrunk the number of computation from the naive model by a factor of ten.
We won’t run through the calculations for the 3×3 covolutions, but they follow the same process as the 5×5 convolutions. Hopefully, this sections cleared up why the 1×1 convolutions are necessary before large convolutions!
That wraps up the specifics of the Inception modules and hopefully clears up any ambiguity. Now time to code our model.
Tensorflow implementation
Coding this up in Tensorflow is more straightforward than elegant. For data, we’ll use the classic MNIST dataset. We didn’t use the typical crazily formatted version, but found this neat site that has the csv version. The architecture of our model will include two Inception modules and one fully connected hidden layer before our output layer. You’ll definitely want to use your GPU to run the code, or else it’ll will take hours to days to train. If you don’t have a GPU, you can check to see if your model works by using just a couple hundred training steps. Depending on your computer, you might get a resource exhaust error and will have to shrink some of the parameters to get the code to run; in fact, I wasn’t able to use the parameters described in the paper which is why mine are smaller. On the other hand, if your machine can handle more parameters, you’ll be able to make your network wider and/or deeper.
Imported libraries
We’ll use pandas and numpy to preprocess the data and Tensorflow for the neural net.
import pandas as pd
import numpy as np
import tensorflow as tf
The images, represented by rows in the table, need to be separated from the labels. Additionally, The labels need to be one-hot encoded.
#get labels in own array
train_lb=np.array(train_set[0])
test_lb=np.array(test_set[0])
#one hot encode the labels
train_lb=(np.arange(10) == train_lb[:,None]).astype(np.float32)
test_lb=(np.arange(10) == test_lb[:,None]).astype(np.float32)
#drop the labels column from training dataframe
trainX=train_set.drop(0,axis=1)
testX=test_set.drop(0,axis=1)
#put in correct float32 array format
trainX=np.array(trainX).astype(np.float32)
testX=np.array(testX).astype(np.float32)
Next, reformat the data so its a 4D tensor.
#reformat the data so it's not flat
trainX=trainX.reshape(len(trainX),28,28,1)
testX = testX.reshape(len(testX),28,28,1)
It’ll be good to have a validation set so we can monitor how training is going.
#get a validation set and remove it from the train set
trainX,valX,train_lb,val_lb=trainX[0:(len(trainX)-500),:,:,:],trainX[(len(trainX)-500):len(trainX),:,:,:],\
train_lb[0:(len(trainX)-500),:],train_lb[(len(trainX)-500):len(trainX),:]
I ran into memory issues when trying to test all my data at once, so I created this class that’ll batch data.
#need to batch the test data because running low on memory
class test_batchs:
def __init__(self,data):
self.data = data
self.batch_index = 0
def nextBatch(self,batch_size):
if (batch_size+self.batch_index) > self.data.shape[0]:
print "batch sized is messed up"
batch = self.data[self.batch_index:(self.batch_index+batch_size),:,:,:]
self.batch_index= self.batch_index+batch_size
return batch
#set the test batchsize
test_batch_size = 100
Before we start building models, create a function that’ll compute the accuracy from predictions and corresponding labels.
#returns accuracy of model
def accuracy(target,predictions):
return(100.0*np.sum(np.argmax(target,1) == np.argmax(predictions,1))/target.shape[0])
Model
It’s good to save our model after training so we can continue training without starting from scratch. This specific command will only work if you’re running linux.
#use os to get our current working directory so we can save variable there
file_path = os.getcwd()+'/model.ckpt'
Set hyperparameters.
batch_size: training batch size
map1: number of feature maps output by each tower inside the first Inception module
map2: number of feature maps output by each tower inside the second Inception module
num_fc1: number of hidden nodes
num_fc2: number of output nodes
reduce1x1: number of feature maps output by each 1×1 convolution that precedes a large convolution
dropout: dropout rate for nodes in the hidden layer during training
Time for the bulk of the work, which will require Tensorflow. Once the graph is defined, create placeholders that hold the training data, training labels, validation data, and test data. Then create some helper functions which assist in defining tensors, 2D convolutions, and max pooling. Next, use the helper functions and hyperparameters to create variables in both Inception modules. Then, create another function that takes data as input and passes it through the Inception modules and fully connected layers and outputs the logits. Finally, define the loss to be cross-entropy, use Adam to optimize, and create ops for converting data to predictions, initializing variables, and saving all variables in the model.
graph = tf.Graph()
with graph.as_default():
#train data and labels
X = tf.placeholder(tf.float32,shape=(batch_size,28,28,1))
y_ = tf.placeholder(tf.float32,shape=(batch_size,10))
#validation data
tf_valX = tf.placeholder(tf.float32,shape=(len(valX),28,28,1))
#test data
tf_testX=tf.placeholder(tf.float32,shape=(test_batch_size,28,28,1))
def createWeight(size,Name):
return tf.Variable(tf.truncated_normal(size, stddev=0.1),
name=Name)
def createBias(size,Name):
return tf.Variable(tf.constant(0.1,shape=size),
name=Name)
def conv2d_s1(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool_3x3_s1(x):
return tf.nn.max_pool(x,ksize=[1,3,3,1],
strides=[1,1,1,1],padding='SAME')
#Inception Module1
#
#follows input
W_conv1_1x1_1 = createWeight([1,1,1,map1],'W_conv1_1x1_1')
b_conv1_1x1_1 = createWeight([map1],'b_conv1_1x1_1')
#follows input
W_conv1_1x1_2 = createWeight([1,1,1,reduce1x1],'W_conv1_1x1_2')
b_conv1_1x1_2 = createWeight([reduce1x1],'b_conv1_1x1_2')
#follows input
W_conv1_1x1_3 = createWeight([1,1,1,reduce1x1],'W_conv1_1x1_3')
b_conv1_1x1_3 = createWeight([reduce1x1],'b_conv1_1x1_3')
#follows 1x1_2
W_conv1_3x3 = createWeight([3,3,reduce1x1,map1],'W_conv1_3x3')
b_conv1_3x3 = createWeight([map1],'b_conv1_3x3')
#follows 1x1_3
W_conv1_5x5 = createWeight([5,5,reduce1x1,map1],'W_conv1_5x5')
b_conv1_5x5 = createBias([map1],'b_conv1_5x5')
#follows max pooling
W_conv1_1x1_4= createWeight([1,1,1,map1],'W_conv1_1x1_4')
b_conv1_1x1_4= createWeight([map1],'b_conv1_1x1_4')
#Inception Module2
#
#follows inception1
W_conv2_1x1_1 = createWeight([1,1,4*map1,map2],'W_conv2_1x1_1')
b_conv2_1x1_1 = createWeight([map2],'b_conv2_1x1_1')
#follows inception1
W_conv2_1x1_2 = createWeight([1,1,4*map1,reduce1x1],'W_conv2_1x1_2')
b_conv2_1x1_2 = createWeight([reduce1x1],'b_conv2_1x1_2')
#follows inception1
W_conv2_1x1_3 = createWeight([1,1,4*map1,reduce1x1],'W_conv2_1x1_3')
b_conv2_1x1_3 = createWeight([reduce1x1],'b_conv2_1x1_3')
#follows 1x1_2
W_conv2_3x3 = createWeight([3,3,reduce1x1,map2],'W_conv2_3x3')
b_conv2_3x3 = createWeight([map2],'b_conv2_3x3')
#follows 1x1_3
W_conv2_5x5 = createWeight([5,5,reduce1x1,map2],'W_conv2_5x5')
b_conv2_5x5 = createBias([map2],'b_conv2_5x5')
#follows max pooling
W_conv2_1x1_4= createWeight([1,1,4*map1,map2],'W_conv2_1x1_4')
b_conv2_1x1_4= createWeight([map2],'b_conv2_1x1_4')
#Fully connected layers
#since padding is same, the feature map with there will be 4 28*28*map2
W_fc1 = createWeight([28*28*(4*map2),num_fc1],'W_fc1')
b_fc1 = createBias([num_fc1],'b_fc1')
W_fc2 = createWeight([num_fc1,num_fc2],'W_fc2')
b_fc2 = createBias([num_fc2],'b_fc2')
def model(x,train=True):
#Inception Module 1
conv1_1x1_1 = conv2d_s1(x,W_conv1_1x1_1)+b_conv1_1x1_1
conv1_1x1_2 = tf.nn.relu(conv2d_s1(x,W_conv1_1x1_2)+b_conv1_1x1_2)
conv1_1x1_3 = tf.nn.relu(conv2d_s1(x,W_conv1_1x1_3)+b_conv1_1x1_3)
conv1_3x3 = conv2d_s1(conv1_1x1_2,W_conv1_3x3)+b_conv1_3x3
conv1_5x5 = conv2d_s1(conv1_1x1_3,W_conv1_5x5)+b_conv1_5x5
maxpool1 = max_pool_3x3_s1(x)
conv1_1x1_4 = conv2d_s1(maxpool1,W_conv1_1x1_4)+b_conv1_1x1_4
#concatenate all the feature maps and hit them with a relu
inception1 = tf.nn.relu(tf.concat(3,[conv1_1x1_1,conv1_3x3,conv1_5x5,conv1_1x1_4]))
#Inception Module 2
conv2_1x1_1 = conv2d_s1(inception1,W_conv2_1x1_1)+b_conv2_1x1_1
conv2_1x1_2 = tf.nn.relu(conv2d_s1(inception1,W_conv2_1x1_2)+b_conv2_1x1_2)
conv2_1x1_3 = tf.nn.relu(conv2d_s1(inception1,W_conv2_1x1_3)+b_conv2_1x1_3)
conv2_3x3 = conv2d_s1(conv2_1x1_2,W_conv2_3x3)+b_conv2_3x3
conv2_5x5 = conv2d_s1(conv2_1x1_3,W_conv2_5x5)+b_conv2_5x5
maxpool2 = max_pool_3x3_s1(inception1)
conv2_1x1_4 = conv2d_s1(maxpool2,W_conv2_1x1_4)+b_conv2_1x1_4
#concatenate all the feature maps and hit them with a relu
inception2 = tf.nn.relu(tf.concat(3,[conv2_1x1_1,conv2_3x3,conv2_5x5,conv2_1x1_4]))
#flatten features for fully connected layer
inception2_flat = tf.reshape(inception2,[-1,28*28*4*map2])
#Fully connected layers
if train:
h_fc1 =tf.nn.dropout(tf.nn.relu(tf.matmul(inception2_flat,W_fc1)+b_fc1),dropout)
else:
h_fc1 = tf.nn.relu(tf.matmul(inception2_flat,W_fc1)+b_fc1)
return tf.matmul(h_fc1,W_fc2)+b_fc2
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(model(X),y_))
opt = tf.train.AdamOptimizer(1e-4).minimize(loss)
predictions_val = tf.nn.softmax(model(tf_valX,train=False))
predictions_test = tf.nn.softmax(model(tf_testX,train=False))
#initialize variable
init = tf.initialize_all_variables()
#use to save variables so we can pick up later
saver = tf.train.Saver()
To train the model, set the number of training steps, create a session, initialize variables, and run the optimizer op for each batch of training data. You’ll want to see how your model is progressing, so run the op for getting your validation predictions every 100 steps. When training is done, output the test data accuracy and save the model. I also created a flag use_previous that allows you to load a model from the file_path to continue training.
num_steps = 20000
sess = tf.Session(graph=graph)
#initialize variables
sess.run(init)
print("Model initialized.")
#set use_previous=1 to use file_path model
#set use_previous=0 to start model from scratch
use_previous = 1
#use the previous model or don't and initialize variables
if use_previous:
saver.restore(sess,file_path)
print("Model restored.")
#training
for s in range(num_steps):
offset = (s*batch_size) % (len(trainX)-batch_size)
batch_x,batch_y = trainX[offset:(offset+batch_size),:],train_lb[offset:(offset+batch_size),:]
feed_dict={X : batch_x, y_ : batch_y}
_,loss_value = sess.run([opt,loss],feed_dict=feed_dict)
if s%100 == 0:
feed_dict = {tf_valX : valX}
preds=sess.run(predictions_val,feed_dict=feed_dict)
print "step: "+str(s)
print "validation accuracy: "+str(accuracy(val_lb,preds))
print " "
#get test accuracy and save model
if s == (num_steps-1):
#create an array to store the outputs for the test
result = np.array([]).reshape(0,10)
#use the batches class
batch_testX=test_batchs(testX)
for i in range(len(testX)/test_batch_size):
feed_dict = {tf_testX : batch_testX.nextBatch(test_batch_size)}
preds=sess.run(predictions_test, feed_dict=feed_dict)
result=np.concatenate((result,preds),axis=0)
print "test accuracy: "+str(accuracy(test_lb,result))
save_path = saver.save(sess,file_path)
print("Model saved.")
It should take around one hour to train on a 1060 GPU, and you should have a test accuracy of 98.5%. The accuracy is a little disappointing, because simpler convnets do just as well and take much less time to train, like this example from Tensorflow; but MNIST is infamous for being too easy these days, and these modules earned their reputation from a much more difficult classification task (around 1,000 different labels). I hope this post helped explain the magic behind Inception modules and/or that the code aided in your understanding. The full notebook with all the code can be found on my GitHub.
While at the airport reading “The Singularity is Near: 2045,” Ray Kurzweil persuaded me to code up a simple genetic algorithm (GA). The concept of GAs are pretty simply: start with a set of solutions and allow the best ones to survive and have offspring.
A simple application is in airline routing problems. Airlines have finite resources and must choose which flights to take in order to maximize their profits (airlines are an extreme example because of how low of margins they operate under).
In this post, we’ll walk through how to program a genetic algorithm in python to solve a linear maximization problem with linear constraints.
Solutions
We let a solution take the form , and a population or set of solutions takes the form . The analogy to genetics is that a solution is like a strand of DNA, and just like each gene can take a state, each element of our solution vector can take a state. In this example, we restrict our states to be binary so .
#generates a 1D array (solution) of zeros and ones with probability p
#
#input: random 1d array with values in [0,1)
#output: converts values to 1 if element < p
def init_1D_p(x,p=0.5):
for i in range(len(x)):
if x[i] < p:
x[i] = 1
else:
x[i]=0
return x
#initializes k 1D solutions of length n
#
#output: row i is solution i
def init_solns_1D(k,n,p=0.5):
solns = np.zeros((k,n))
for i in range(k):
solns[i] = init_1D_p(np.random.rand(n),p)
return solns
Objective
In general, we will wish to either maximize or minimize some objective function that takes a solution as an input. We will assume that we wish to maximize (the assumption to maximize isn’t important since we can just maximze the negative of an objective function if we wanted the minimization) a linear function
where .
#x: solutions with each row as a solution
#o: coefficients of objective function
def Linear_Objective(x):
o = np.array([1,2,3])
return np.dot(x,o)
Constraints
The solution will have to be feasible, meaning that it must satisfy some constraints.
Solutions must exist in a feasible region (image source)
We will deal with just one linear constraint
In our airline example, the coefficient of could be the amount of resource flight is using, is the total amount of resources, and is the amount of profit for flight
#x: solutions with each row as a solution
#c: coefficients so c_i is constraint coefficient for x_i
#ub: the upperbound
#
#return: boolean value; true if contraint satisfied
def Constraint1_UpperBound(x,c,ub):
return np.dot(x,c)<ub
Mating
An offspring, is created by mating two solutions, , so that the kth element of the offspring is
where .
The offspring solution is a mixture of both parent solutions (image source)
#mates x1 and x2 and randomizes elements from child < p
def mate_1D(x1,x2):
rand_mate=np.random.rand(len(x1))
result= np.zeros(len(x1))
for i in range(len(x1)):
if rand_mate[i] < 0.5:
result[i] = x1[i]
else:
result[i] = x2[i]
return result
Mutations
After all evaluations have been made and offspring have replaced failed solutions, we introduce random mutations to each element of each member in the population.
DNA example of a mutation in the genome (image source)
We let each element of a solution mutate, or switch states, with probability .
#applies random mutations to elements of x with probability p
def random_mutation_1D(x,p=.01):
import random
rand_mate=np.random.rand(len(x))
for i in range(len(x)):
if rand_mate[i]<p:
x[i] = random.sample([0,1],1)[0]
return x
Process and Simulations
We can view implementing our genetic algorithm as a process, where the state of each element of our process is the . To get the next generation of solutions (or next state in our process), we take the current population, evaluate all the members via the objective function and constraints, apply mating, and finally apply mutations; we keep doing this for as long as many iterations as we’d like our simulation to last. The remainder of this section goes through the details of coding up the simulation.
We will simulate a generation by evaluating each member of the population via the objective function and the constraints.
# return: booleans that are true if the index contains a working solution
def getWorkingSolutionIndices(constraint_results):
#results = np.array(sum(constraint_results))
results = []
for i in range(len(constraint_results)):
if constraint_results[i] == True:
results.append(i)
return np.array(results)
If the member does not satisfy all constraints, we will replace it by offspring of two members of the current generation that do satisfy the constraints; additionally, we will pick these members so that solutions that have a better objective measure have a greater probability of being chosen for mating. To do this, we create a probability mass function (pmf) where the probability of selecting a solution is proportional to how well it did on the objective function.
#returns a probability distribution with weighted values
#corresponding to objective solutions that satisfy constraints
def getPDF(solns,working_soln_ind,obj_results):
total = sum(obj_results[working_soln_ind])
prob = np.zeros(len(solns))
for i in working_soln_ind:
prob[i]=obj_results[i]/total
return prob
Now, to sample from this pmf we get the cumulative distribution function (cmf) and generate a uniform random variable.
#input:a probability mass function
#output: corresponding cdf
def getCDF(pmf):
cdf = np.zeros(len(pmf))
running_total = 0
for i,p in enumerate(pmf):
running_total += p
cdf[i] = running_total
return cdf
#samples pmf once and returns the index of the random sample
def sample_p_dist(pmf):
cdf = getCDF(pmf)
rand_num = random.random()
return np.argmax(cdf==cdf[np.argmax(cdf>rand_num)])
Since the big picture idea of applying a genetic algorithm is to find a good solution to our objective functions, we should store each feasible solution and its objective value.
def updateSolnToResult(solns,dictionary,objective_function,obj_coef):
for soln in solns:
dictionary[str(soln)]=objective_function(soln,obj_coef)
return dictionary
Now for simulating our algorithm we set some hyper-parameters and make sure to store the good results.
#reinitialize the solns
solnToResult={}
solns = init_solns_1D(num_solns,3)
#implementation that cares about satisfying constraint and maximizing our function
for _ in range(num_steps):
new_solns = np.zeros((num_solns,3))
obj_results = Linear_Objective(solns) #get objective value for each solution
c1_results = Constraint1_UpperBound(solns) #check constraints
#get working solution indices
working_soln_ind = getWorkingSolutionIndices(c1_results)
#get pmf of distribution to sample from
prob = getPDF(solns,working_soln_ind,obj_results)
#replace failed solutions with randmized ones
for i in range(num_solns):
if c1_results[i] == True:
updateSolnToResult(solns[i],solnToResult,Linear_Objective)
if(len(working_soln_ind)>=2): #check if mating is possible
#pick random solution to mate with according to the pmf from weighted obj results
mate_index=sample_p_dist(prob)
offspring = mate_1D(solns[i],solns[mate_index])
else:
offspring = solns[i]
else: #replace it with a some working solutions
if(len(working_soln_ind)<=2): #check if mating is possible
mate_index1,mate_index2 = sample_p_dist(prob),sample_p_dist(prob)
offspring = mate_1D(solns[mate_index1],solns[mate_index2])
else: #replace it with a some random solutions
offspring = init_1D_p(np.random.rand(3))
new_solns[i] = offspring
solns = mutate(new_solns) #reset the solution set and mutate
print solns
Conclusion
That’s all there is to it! This was a simple example, but if you need to program a genetic algorithm for more complicated problems, you should be able to follow this basic outline. To view a notebook with all the code, check out my github.
As of mid September, Tensorflow is easy to install if all you want to use is a CPU. As someone with no experience using Cuda, installing GPU drivers on Ubuntu or using Bazel, I ran into a panoply of issues installing Tensorflow with 10-series GPU support:
10-series GPUs require CUDA 8RC for the libraries to work properly
CUDA 8.0 won’t work with the Tensorflow packages on on the tensorflow website so you’ll have to build from source
the current source code on github has bugs that need manual repairs.
After a weekend, I finally got Tensorflow to work with an EVGA GTX 1060 GPU. In this post, I’ll go through my steps starting with preparing your machine before installing the GPU and ending with installing Tensorflow into a conda environment. Although this post assumes Ubuntu 14.04, many of the troubleshooting techniques originated from people using 16.04.
0. Prep your machine
Prepping your machine will take a surprising large amount of time and will come back to bite ya if it’s not done correctly. If you still are having issues with getting your GPU to work with Tensorflow, it’s probably because something went wrong here. I’d suggest doing this part carefully.
Removing previous drivers and modules
To remove previous nvidia drivers use
$ sudo apt-get purge nvidia-*
Check if you have any modules in your kernel by running
$ dkms status
If you get any output, you’ll have to use remove the modules.
nvidia modules
If you have nvidia modules installed, the output would be in the form
This will let Ubuntu use nouveau drivers (these are reverse engineered drivers not created by nvidia) so that you can use your GPU before installing the nvidia driver (step 4).
1. Physically install the GPU
This will hopefully be the easiest part of the install. If you’ve never installed a graphics card, there are plenty of youtube videos to help. Make sure that you install the card into a PCIe 3.0 to get the best performance.
2. Install CUDA 8.0RC
Download the CUDA Toolkit 8.0RC from nvidia (you’ll need to signup by giving them your email). For the installer type, I used the deb (local) method, but people have had success using the runfile.
Just add the package and install.
$ cd ~/Downloads
$ sudo dpkg -i cuda-repo-ubuntu1404-8-0-rc_8.0.27-1_amd64.deb
$ sudo apt-get update
$ sudo apt-get install cuda
3. cuDNN v5.1
You’ll need to download the cuDNN v5.1, which is a library for machine learning, from nvidia (you’ll need to respond to a survey and accept terms before downloading).
Next, unpack cuDNN, copy the files into the cuda folders, and set permisions.
Make sure to select the correct series, product, and OS. Then you should be directed to the 367.44 driver, which you should download.
The easiest way to install the driver is to use the GUI so you won’t have to mess with stopping Xorg. Ubuntu should be able to find the downloaded driver if it’s in your Downloads folder. Open up Additional Drivers by using the GUI,
or open a terminal and enter
$ software-properties-gtk --open-tab=4
You should see the 367.44 driver; select it and apply.
5. Reboot
Now that you think the driver is installed, it’s good to reboot the machine
$ sudo reboot
and make sure everything works.
If you’re drivers are properly installed, everything will boot like normal. You’ll know your drivers aren’t working if, when Ubuntu tries to start, your monitor turns purple or black and stays that color. You can try to go back and repeat single steps, but you might have to restart this process by going back to step 0 and working your way back here.
6. Install Bazel
To install Bazel, you can follow the instructions on their site, but they are repeated here.
It doesn’t matter where you clone it into (I chose the home directory), because you’ll use Bazel to build a pip wheel that you then can use with pip to install where ever you’d like.
8. Fix errors in current Tensorflow
It turns out that there are some errors (As of September 11th) in the source code (see this discussion), so you’ll need to manually edit some of the BUILD files. For each edit, just search for the key term in the specified location and comment out per the instructions.
comment instructions: Search for if_mobile or if_android and you should find 5 occurrences. For the first occurrence, inside load, you don’t need to comment anything out.
For the other 4 occurrences, you’ll need to comment out the if_mobile, if_android, and if_ios conditions as shown below.
9. Install Anaconda
If you haven’t already, install anaconda by following these directions. It helps to do this before configuring the Bazel build because anaconda has all the packages that Tensorflow needs to compile.
10. Configure the build
To configure the Bazel build, go to the root of your tensorflow directory (the code below assumes it is in the home directory) and run the configure file.
$ cd ~/tensorflow
$ ./configure
Then make sure to accept the GPU installation and you can get away with accepting the defaults for the rest.
10. Compile Tensorflow with Bazel
To build Tensorflow from source, use these Tensorflow instructions which are repeated here.
11. Set up conda environment to install tensorflow
The name of the conda environment will be “tensorflow.” Install all anaconda packages (so you can use stuff like jupyter notebook right away).
$ conda create --name tensorflow anaconda
UPDATE: If attempting to install in a conda environment, make sure not to specify the python version (e.g. python=2.7). For some reason, when you install the Tensorflow pip package, all your numpy packages will break (even outside the environment!), and you’ll have to reinstall anaconda.
12. Install Tensorflow
First, activate the environment that Tensorflow will be installed in, then install Tensorflow.




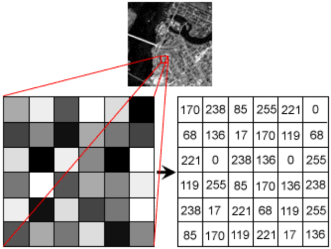


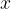
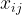
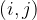


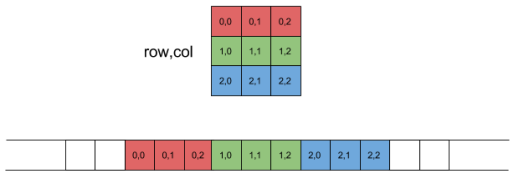
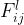



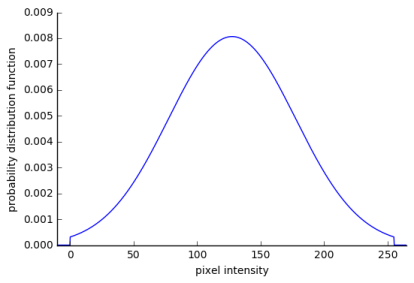


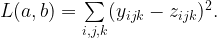












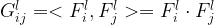
![G(F^l) =\left[\begin{array}{cccc}G^l_{11}&G^l_{12}&\dots&G^l_{1N_l}\\ G^l_{21}&G_{22}&\dots&G^l_{2N_l}\\ \vdots&\vdots&\ddots&\vdots \\ G^l_{N_l1}&G^l_{N_l2}&\dots&G^l_{N_lN_l} \end{array}\right],](https://s0.wp.com/latex.php?latex=G%28F%5El%29+%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7DG%5El_%7B11%7D%26G%5El_%7B12%7D%26%5Cdots%26G%5El_%7B1N_l%7D%5C%5C+G%5El_%7B21%7D%26G_%7B22%7D%26%5Cdots%26G%5El_%7B2N_l%7D%5C%5C+%5Cvdots%26%5Cvdots%26%5Cddots%26%5Cvdots+%5C%5C+G%5El_%7BN_l1%7D%26G%5El_%7BN_l2%7D%26%5Cdots%26G%5El_%7BN_lN_l%7D+%5Cend%7Barray%7D%5Cright%5D%2C&bg=ffffff&fg=000000&s=1&c=20201002)
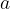


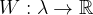
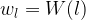
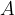

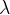
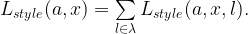





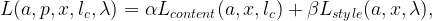


.
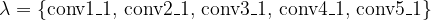
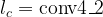



 and the model’s state of the previous time-step. This is shown in Figure 2.
and the model’s state of the previous time-step. This is shown in Figure 2.




 and the current input is being transformed by
and the current input is being transformed by  . Both of these go into the hidden layer node, and thus there must be some operation that combines these two transformations. You can do this by concatenating, summing element-wise, multiplying element-wise, etc. In my implementations, I made sure that the dimensionality of
. Both of these go into the hidden layer node, and thus there must be some operation that combines these two transformations. You can do this by concatenating, summing element-wise, multiplying element-wise, etc. In my implementations, I made sure that the dimensionality of 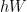 equaled the dimensionality of
equaled the dimensionality of  so that element-wise operations were possible, but I found that concatenating yielded the best results (I do include a version of the implementation with element-wise addition in my
so that element-wise operations were possible, but I found that concatenating yielded the best results (I do include a version of the implementation with element-wise addition in my  , but the linear combinations of both inputs cannot be recovered with element-wise operations.
, but the linear combinations of both inputs cannot be recovered with element-wise operations.





 transforms its inputs, but it can’t transform the inputs.
transforms its inputs, but it can’t transform the inputs. .
.


 . We need to pick, ahead of time, a value
. We need to pick, ahead of time, a value 
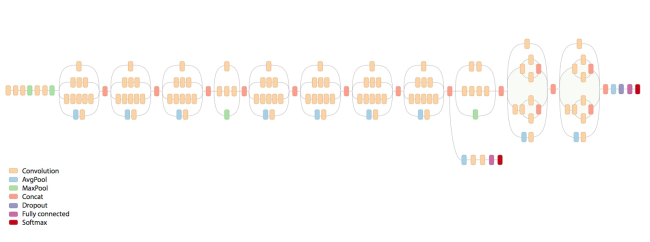
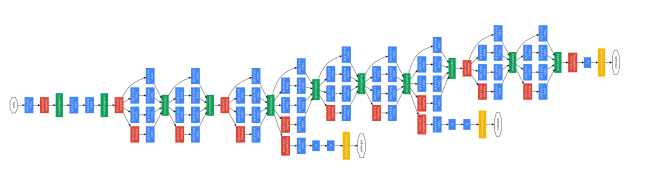

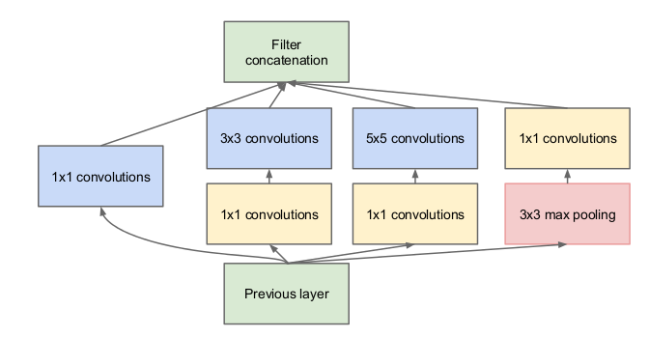
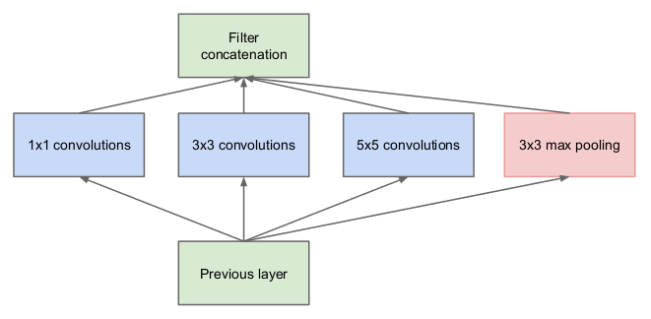
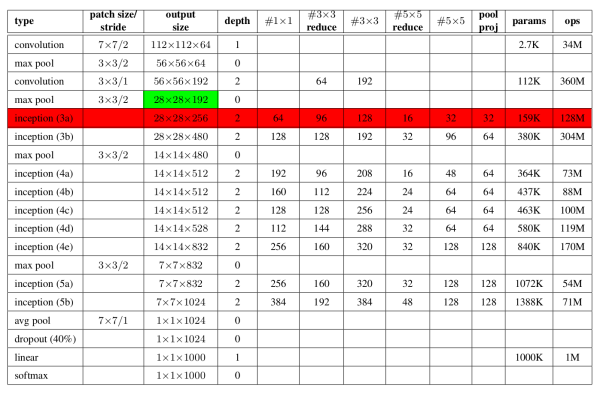


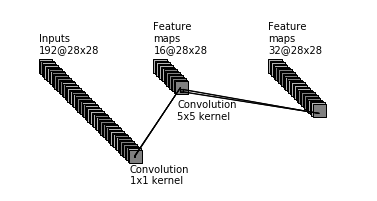
![[(1^2)(28^2)(192)(16)]+[(5^2)(28^2)(16)(32)]=2,408,448+10,035,200= 12,443,648\text{ operations.}](https://s0.wp.com/latex.php?latex=%5B%281%5E2%29%2828%5E2%29%28192%29%2816%29%5D%2B%5B%285%5E2%29%2828%5E2%29%2816%29%2832%29%5D%3D2%2C408%2C448%2B10%2C035%2C200%3D+12%2C443%2C648%5Ctext%7B+operations.%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 , and a population or set of
, and a population or set of  solutions takes the form
solutions takes the form  . The analogy to genetics is that a solution is like a strand of DNA, and just like each gene can take a state, each element of our solution vector can take a state. In this example, we restrict our states to be binary so
. The analogy to genetics is that a solution is like a strand of DNA, and just like each gene can take a state, each element of our solution vector can take a state. In this example, we restrict our states to be binary so  .
.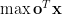
 .
.
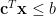
 could be the amount of resource flight
could be the amount of resource flight  is using,
is using,  is the total amount of resources, and
is the total amount of resources, and  is the amount of profit for flight
is the amount of profit for flight  is created by mating two solutions,
is created by mating two solutions,  , so that the kth element of the offspring is
, so that the kth element of the offspring is
 .
.

 .
. . To get the next generation of solutions (or next state in our process), we take the current population, evaluate all the members via the objective function and constraints, apply mating, and finally apply mutations; we keep doing this for as long as many iterations as we’d like our simulation to last. The remainder of this section goes through the details of coding up the simulation.
. To get the next generation of solutions (or next state in our process), we take the current population, evaluate all the members via the objective function and constraints, apply mating, and finally apply mutations; we keep doing this for as long as many iterations as we’d like our simulation to last. The remainder of this section goes through the details of coding up the simulation.









{kind=link}