Imagine that you have two images, and you want to create a new image based on some combination of the features of these images. What if you could use the style of one image and the content of the other to create this new image? For example, let’s say you have an image of the Hokusai’s The Great Wave of Kanagawa and a photo of the Seattle skyline, and you want to create a new picture that has the Seattle skyline painted in the pastel, oceanic, and foamy style of The Great Wave of Kanagawa.


This task only seems possible via incredible artistic talent and obscure “vision.” But you can actually develop a systematic method to accomplish this.


In fact, this process can be applied to any pair of style-content images to generate stellar results. The authors of A Neural Algorithm of Artistic Style figured out this process. This post will discuss how they did it.
Basic ideas
Computer vision
If you’ve never dealt with computer vision, it’s worth explaining how an image is represented in a computer. Let’s say your computer displays a black-and-white image. Your computer sees this image as nothing but a 2D map (this is not actually true, because those file extensions like jpeg and png are telling your computer the compression format, but just know that you can get this 2D map from your compressed image). You can think of this 2D map as a grid, where each element in the grid represents a pixel.
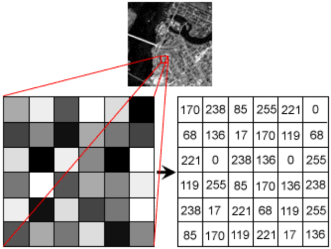
A pixel has an intensity that falls between 0 and 255, where 0 is not intense and 255 is super intense. In our black and white image, an intensity of 0 would be a black, 255 would be white, and anywhere in between would be grey.

A color image in your computer is nothing but three 2D maps, one for each primary color (red, green, and blue).

Each map represents the pixel intensities for one of those primary colors. For example, if you had an image that was pure red, you would expect only one of the maps to have non-zero pixels.
Mathematically, we can represent images similarly to how a computer would represent the images using tensors. For a gray-scale image, an image 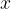
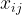
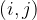

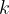
Convolutional neural networks
The most important tool for generating novel and stylish images is the convolutional neural network (CNN). To fully understand CNNs will take much more time than what this post allows, but luckily you don’t need to fully understand them to know how they’re used to generate art. A bit of history on how they came to be and a brief summary on how they operate should suffice.
CNNs are traditionally used in image object recognition tasks where images are fed into the CNN, and the CNN outputs a bunch of probabilities about what the main object is in the image (e.g. if you gave a CNN an image of a leopard, you would expect it output a how probability of a leopard).

In the case of image recognition, you can just think of CNN as a mathematical function that takes images as inputs and has probabilities as outputs. But in our case, we actually need to understand a bit more to be able to use them to generate new images.
CNNs achieve their object recognition expertise via transforming the input image through a series of layers, where each layer has a set of feature maps which represents certain features present in the image.
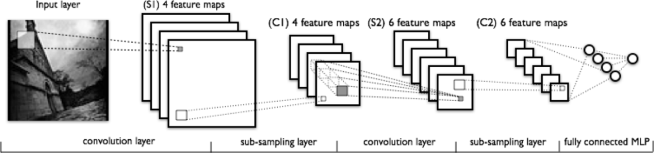
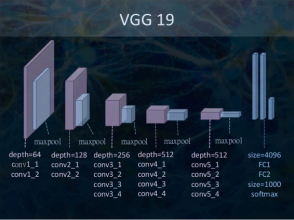
The authors learned that when you pass an image through a deep CNN (they used a modified version of VGG 19, which is a specific type of CNN) trained to perform well for image recognition (their network was trained on ImageNet), you could actually extract the image’s style and content from these feature maps.
A feature map can be represented in two ways: a 2D grid of values or a 1D vector of values. Intuitively, it make sense to think of a feature map as a 2D grid of values, because the feature map really is a 2D map of feature locations that correspond to the locations on the original image.
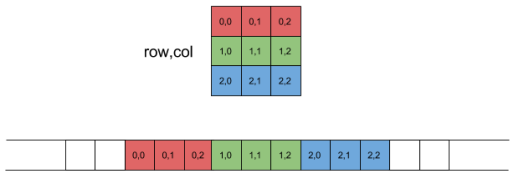
But if we are being pragmatic, we should be able to stretch out this 2D map into a long vector (1D tensor). This is actually how a lot of operations happen when convolutional networks are implemented.
We will be interested in referencing specific feature map values, so we define 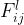



Calculus with images
Before moving on to the details of the original paper, it’s important to recognize one more important tool that drives most of the results: using calculus to change images. Ultimately, if there is some function that describes the similarity or distance between two variables (and this function is differentiable), calculus can be used to describe how to change those variables so they are closer to each other. In our case, calculus can be used to change the values of pixels from an image until the image meets some criterion.
For example, let’s say we have two images: Vincent van Gogh’s The Starry Night and a white noise image–this is just an image that has pixel values sampled from a normal distribution that’s centered at 255/2 and truncated at 0 and 255.
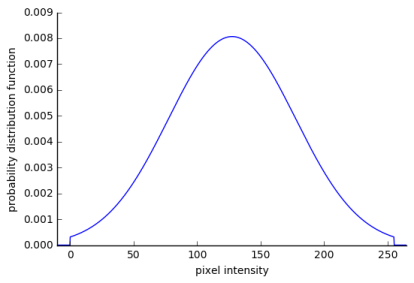
The white noise image can be changed to look like The Starry Night by comparing each pixel of the two images, quantifying how much they differ, and then changing the white noise image accordingly.


The difference between two images 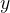
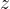
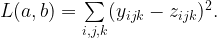
This sum of errors is a loss quantifying the difference between two images. This loss is differentiable with respect to the pixels of the white noise image, and thus we can quantify how to change the pixel values in the white noise image to get the two images closer.

Once we change the white noise image to get a little closer to The Starry Night, we can again measure the loss and differentiate to find out what changes to make. This process can be repeated until the white noise image and The Starry Night image are indistinguishable.
Content reconstruction
In order to create new image using a blend of content and style, we first need a procedure/method that creates a new image which has content (i.e. the image scene) that matches the content of some other image; this method is known as content reconstruction. Reconstructing an image from its content can be done using CNNs, and it’s more straightforward than the reconstruction of style.
First, define a set of feature maps that will be used as criteria in content assessment. This is done by choosing a layer 



Differentiating this loss function with respect to the white noise image will yield derivatives of the loss with respect to pixels of the image. These derivatives can be used to change the white noise image so it has content closer to the content of the content image according to the feature maps in layer





Reconstructions that use earlier layers in the network preserve pixel details, whereas reconstructions with later layers lose details but preserve salient features (e.g. the reconstruction of an image that contained a house will still contain a house, but it might have something like a blurry window).
Style reconstruction
Reconstructing style of an image is less intuitive than reconstructing content, but it uses the same principles. Like content reconstruction, a set of feature maps 

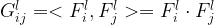
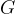
![G(F^l) =\left[\begin{array}{cccc}G^l_{11}&G^l_{12}&\dots&G^l_{1N_l}\\ G^l_{21}&G_{22}&\dots&G^l_{2N_l}\\ \vdots&\vdots&\ddots&\vdots \\ G^l_{N_l1}&G^l_{N_l2}&\dots&G^l_{N_lN_l} \end{array}\right],](https://s0.wp.com/latex.php?latex=G%28F%5El%29+%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7DG%5El_%7B11%7D%26G%5El_%7B12%7D%26%5Cdots%26G%5El_%7B1N_l%7D%5C%5C+G%5El_%7B21%7D%26G_%7B22%7D%26%5Cdots%26G%5El_%7B2N_l%7D%5C%5C+%5Cvdots%26%5Cvdots%26%5Cddots%26%5Cvdots+%5C%5C+G%5El_%7BN_l1%7D%26G%5El_%7BN_l2%7D%26%5Cdots%26G%5El_%7BN_lN_l%7D+%5Cend%7Barray%7D%5Cright%5D%2C&bg=ffffff&fg=000000&s=1&c=20201002)
where 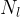
So, for each layer of a CNN, a Gram matrix can be computed that describes the style of an image. Because the authors were mathematicians, they figured that if we had two images we can get two Gram matrices, compare them with some sort of loss function, and then use calculus with the loss and pixels of one of the images to change that image to have style more like the other. Specifically the loss for a layer 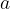

where 
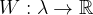
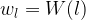
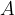

Style generation can be done using multiple layers of the network to take advantage of different aspects of style picked up by the CNN. To do this, we define a set of layers 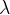
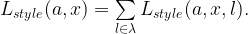
The iterative process of changing a white noise image based off derivatives of a loss with respect to the pixels of the white noise image can be used with the style loss to create new images that have a style strikingly similar to the style image.





The authors figured out that a Gram matrix of an earlier layer in a network describes style at a smaller scale in the image while a Gram matrix of a later layer in the network describes style at a larger scale in the image.
Generating stylish images with content
Images that have the style of one image but the content of another can be generated by jointly changing a white noise image to satisfy style and content criteria simultaneously. To do this, we create a new loss
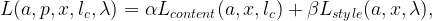
where 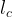

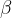

The authors had a list of parameters specifying details like the layers used for creating style in the image. Here is that list:
- ratio of content weight to style weight
.
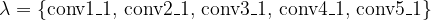
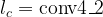

The authors also used L-BFGS for optimization, but I found that Adam with a learning rate of about 1-5 can generate aesthetic results in roughly 500 to 2000 iterations.
Conclusions
Seemingly novel images can be generated that incorporate style from one image and content from another. This remarkable achievement uses convolutional neural networks to extract content and style from individual images while using clever loss functions and calculus to iteratively create new images. People have built upon the work of the original authors to create–again–astonishing computer generated images (Deep Dream and CycleGAN to name a few). The future of AI and its influence to our creative processes are very much in flux, and whatever comes next is sure to be extraordinary. Check out my GitHub for implementation of the full method and for code used to generate images in this post.

{kind=link}
Well done! 🙂 This should be accessible to most audiences who have seen a little bit of linear algebra
LikeLiked by 1 person