Most tutorial, deep learning blog posts that introduce recurrent neural networks (RNNs) use Long Short Term Memory (LSTM) cells in their examples. This happens because training vanilla recurrent neural networks is more difficult, and the results are less impressive. Still, it’s good to understand the basics of RNNs, because the area of sequential modeling is an active area of research with the incumbent state-of-the-art models knowing they won’t stay there for long. Just recently, researchers at Google used reinforcement learning to discover RNN architectures that beat LSTM cells.

I’ll walk through the architecture of simple recurrent neural networks (RNNs) and the corresponding code. For those just getting starting with neural nets for sequential modeling, a great intro to the applications and results of RNNs can be found here. If you want a thorough intro to RNNs, check out parts 1 and 2 of Danny Britz’s RNN posts. The goal of my post will be to share some of the idiosyncrasies that I learned while implementing basic RNNs. I will be using the most basic types of RNNs and won’t include LSTMs or GRUs. Additionally, I’ll explain and implement the two most common architectures of basic RNNs. The implementations will be done in Python using TensorFlow. As a data set I’ll use text8. The goal will be to do character sequence modeling; that is, given a sequence a characters, our model should provide a probability distribution over the characters in our alphabet for the next character in the sequence.
This was my first project having anything to do with natural language processing, and I found that most of my time was spent doing things like setting up batches of data, rather than building the neural networks. The next most time consuming element was understanding how to optimize the network through time. Hopefully this post will save you time or at least guide your experimentation as you begin your RNN journey.
RNN motivation
We want to be able to use previous information (i.e. the history of a sequence) to impact our decision at the current moment. Specifically, we want to be able to summarize the past and input that summary into the current state of our model.

In neural nets, one way to do this would be to have a model that takes in our current input 

Perhaps the most common use of RNNs is modeling text, and that’s what we’re doing in this post. Text is comprised of characters. Text is actually a sequence of characters, and thus should be modeled using something that has the capacity to understand the importance of the sequential relationships between the characters.
I’ll call the set of all characters that our model can understand an alphabet.

The goal of our model will be to provide a probability distribution over the alphabet for the next character in the sequence given what the model has already seen in the sequence.
RNN architectures
The most basic RNN is just a neural network with an extra input, where the extra input usually being the neural network’s hidden layer in the previous time-step (we’ll call this version Arch 1) or the neural network’s output in the previous time-step (we’ll call this version Arch 2). There are advantages to both of these, and they’re talked about in following subsections.
To simplify things further and illustrate the most basic RNN, we can think of an RNN as a system with inputs and outputs.

The system takes in inputs, usually some version of the state of the previous time-step of the RNN cell and the current sequence value (e.g. a character). Then the cell transforms the inputs by means of one or more neural nets and spits out outputs–usually a probability distribution of the next element in the sequence and the current state value. Throughout the post, it may be helpful to think of RNNs in this abstract way.
Arch 1
In Arch 1, our system has two inputs and two outputs. The current value of the sequence (e.g. a character) will be the first input and the model’s previous hidden layer will be the second input. The current output (i.e. the probability distribution of the letters in the alphabet for the next value in the sequence) will be the first output and the hidden layer of the RNN will be the second output (you can think of the hidden layer as the state of model). Figures 4 shows this model in the system view.

To get a detailed view of what this architecture is actually doing, go to Figure 5.

We see that the hidden layer of the previous time step is being transformed by 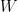

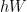


The good thing about this architecture is that the hidden layer is being passed forward. This is nice because the hidden layer can be as large as we’d like and thus should be able to hold a sufficient summary of the history of a sequence that would allow the model to correctly predict the next sequence value.
Arch 2
In Arch 2, our model will have two inputs and one output. The input character will be one input and the model’s previous output will be the second input. The only output will be a probability distribution over the alphabet for the next sequence value. This model is nice, because it is simpler and will allow us to make a neat adjustment in training that should allow the model to train more efficiently. On the downside, the previous output alone won’t be able to provide a detailed history of the sequence, because given only the previous output and the current state, the model’s capacity is effectively reduced to a Markov chain whose state space is the alphabet. Figures 5 and 6 show the Arch 2 model.


With this model using only the previous output, you can use teacher forcing while training; this is just using the true/correct/target output for the second input instead of using the model’s output during training. Then, during test time you use the model’s output instead of the correct output. This is shown in Figure 7.

I suppose that if you knew the correct previous output during test time, you’d use that instead of the model’s output. These models are usually used to generate sequences, which is probably why the authors of Deep Learning said to use the model’s output during test time.
We will implement both models in this post, but we’ll focus on Arch 1, because it has greater modeling capacity.
RNN tragedies
I won’t talk about the main issues with vanilla RNNs here, because they’re extensively mentioned in almost every other resource. But if you are completely new to RNNs, know that they are infamous for having trouble learning due to gradients that both vanish and explode.
Unfortunately, I found that both of the implementations of RNNs are finicky. It took a lot of time to find a way to train the models that actually gave intended results. The most important decision was the choice of a loss function. It turns out that not using the log-likelihood really messes up the training.

So make sure to use standard cross-entropy or your own implementation of the negative log-likelihood loss function while training.
Another big issue was finding a learning rate. You should feel free to experiment with these networks, but you might find it less frustrating to start with the parameters I provide, because finding a combination that trains well is non-trivial.
It’s not surprising that there were difficulties, because that’s what most other people who are proficient in these networks say (and one of the reasons LSTMs are so amazing). Conversely, if you use a gating structure, such as what’s in an LSTM cell, the results are amazing and most of the difficulties go away. I have yet to explore other gating structures, and that might be a topic of a future post (for example, different types of Long Short Term Memory (LSTM) cells, like what Christopher Olah describes here, or Gated Recurrent Units (GRUs)).
Data
We’ll use the text8 dataset, which is a lot of cleaned up text that was scraped from about 100,000 wikipedia pages. The text will only contain lowercase letters “a” through “z”. The data can be downloaded with the following function, which I found from Udacity’s Deep Learning course.
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
"""Download a file if not present, and make sure it's the right size."""
if not os.path.exists(filename):
filename, _ = urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified %s' % filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
Then this function can be used to read the data into memory.
def read_data(filename):
f = zipfile.ZipFile(filename)
for name in f.namelist():
return tf.compat.as_str(f.read(name))
f.close()
text = read_data(filename)
print('Data size %d' % len(text))
The text variable should be one string that’s 10 million characters long.
Alphabet
I like to create a globally defined alphabet, so we know exactly what characters we’re modeling. This gives us flexibility later on if we should to include more characters. Of course, with the current data this won’t be possible, because we are using a cleaned version of text that only includes lowercase English letters “a” through”z” and the space character.
alphabet = ' '+string.ascii_lowercase global alphabet alphabet_size = len(alphabet)
Next up is to write some helper functions for dealing with our data. Our model will required numerical versions of characters. First, let’s create a one-to-one mapping from characters to integers.
#character to int
def char2id(x):
if x in alphabet:
return alphabet.find(x)
else:
return 0
#id to char
def id2char(x):
return alphabet[x]
Second, the integers will need to be one-hot encoded so they can be fed into the model.
#letter to one_hot encoded vector
def char2vec(x):
r = np.zeros([alphabet_size],dtype=np.int8)
r[char2id(x)] = 1.0
return r
Lastly, it’ll also be useful to have a function that takes in a one-hot encoded vector and transforms it into a 2D array, because we’ll be doing matrix multiplication with the vector.
#turn the one-hot vector into a matrix
def vec2mat(x):
return np.reshape(x,(1,len(x)))
Probability distributions
If we are using our model to generate sequences, and we have a probability distribution over the elements of our alphabet, we will need to sample from this distribution to choose the next element in our sequence.
def sample_prob(prob):
r=random.random()
s=0
for i,p in enumerate(prob):
s+=p
if s>=r:
return i
return 'Awry sampling probs'
Additionally, it’ll be good to have a function that creates a random distribution over our alphabet for when we initialize our model during sequence generation.
#random distribution
def random_dist():
r = np.random.rand(alphabet_size)
return r/np.sum(r)
Unrollings
In order to compute gradients with respect to previous values of the sequence and their respective transformations, the entire sequence up to the point you wish to differentiate with respect to will need to be inputted during the training step: the implementation of this concept is known as unrolling the network.

To understand the importance of unrollings during training, let’s think about the following example. Suppose our network has zero unrollings during training. That is, during each training step, the network is only given the current input of the sequence and some previous information about the history of the sequence; in Arch 1 the previous information would be the RNN’s previous hidden state while in Arch 2 the previous information would either be the model’s previous output or the previous correct target if teacher forcing is used.

Then, the network is the supposed to output the next value of the sequence, and its output is compared to the target via the loss function. If the current target is highly dependent not on the current value of the sequence but on the previous values of the sequence, the network will only be able to change how the information of the previous values of the sequence that is inputted into the current state of the model is transformed, but not how the information of the previous values is represented. In Figure 11. the network can change how the weight matrix 
Thus, there is an incentive to increase the number of unrollings during training. Unfortunately, as the number of unrollings increases, the gradients used to train the network will either explode or vanish exponentially. The good news is that to keep them from exploding, you can simply pick a ceiling to cap the gradients; this is known as gradient clipping. The bad news is that to keep the gradients from vanishing, you have to use some type of gated RNN (e.g. LSTM), use leaky units, or remove connections; because this post is focusing on vanilla RNNs, we won’t use these and will have to choose a small value for our number of unrollings 
Batches
Generating batches for sequential text models seems strange at first for a few reasons. The main reason is that the like a typical classification problem the model will output a class label (except in this case the goal is to correctly classify the next value in a sequence), but unlike most classification problems the class label will be used both as a model input and a target (the target of the current time-step will be the input at the next time-step). The other reason generating batches seems odd is because the inputs and targets for the entire unrolling need to be generated and inputted into the modeling before computing the loss.
I like to think of one batch of inputs–that is, a matrix with one-hot encoded vectors as rows–as part of a mega batch. The reason for this mega batch has to do with the unrollings that happens in training. You’ll need to feed a batch of inputs for each unrolling during each step of training. There are plenty of ways to do this, but I just created a mega batch for each step of training, where each element of the mega batch is a batch.
class Batch(object):
def __init__(self,text,batch_size):
self.text = text
self.text_size = len(text)
self.batch_size = batch_size
self.segment_size = self.text_size//batch_size
self.cursors = [self.segment_size*b for b in range(batch_size)]
def next(self):
self.cursors = [(c + 1) % self.text_size for c in self.cursors]
x,y = [self.text[c] for c in self.cursors], [self.text[(c+1)%self.text_size] for c in self.cursors]
return x,y
The goal is to predict the next character, so that’s why the labels are just the next character.
There will be batch size many cursors, each keeping track of the index of a sequence of characters. Figure 12 shows the cursors for the first batch, Figure 13 shows the cursors for the second batch, and Figure 14 shows the cursors for the eighth batch.



We’ll create another function that takes in a Batch object and spits out
def getWindowBatch(b,num_unrollings):
window_batch = []
for i in range(num_unrollings):
window_batch.append(b.next())
window_batch=zip(*window_batch)
x,y = list(window_batch[0]),list(window_batch[1])
return x,y
Maybe you noticed that the class doesn’t actually create a mega batch, and you’re correct. We create a mega batch for the input characters and labels the same way: by indexing through the unrollings and batch size.
#trains x
mega_batch_x = [] #each elemnt will be a batch. there will be n elements where n is the number of unrollings
for n in range(num_unrollings):
batch = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
for ba in range(batch_size):
batch[ba]=char2vec(batch_x[n][ba])
mega_batch_x.append(batch)
Hyperparameters and initial conditions
Training these networks is the toughest part. You’ll have to take special care creating batches, saving/passing variables, picking parameters, and computing gradients.
Let’s say we have a batch size of 
We will one-hot encode the characters so each mega batch will have
You might be wondering what to use as the initial input, because if we haven’t run our model we won’t have a previous output or hidden layer to pass into the current model. I couldn’t find a standard for this, so I just initialized the extra input as a vector of all zeros.
I set the learning rate to do an exponential decay, mostly because the learning rate has a huge impact on training performance, and the decay allowed me to see which ranges were behaving the best. In general, I found that a learning rate of in the range of 0.1 and 2.5 is where most of the learning happens.
Implementations in TensorFlow
Both architectures are tricky to get working in TensorFlow. Before training, the entire graph will need to be defined, which means that placeholders need to be defined for inputs and target values of each unrolling. Normally, we would define a placeholder on a graph using something like this
a = tf.placeholder(tf.float32,shape=(batch_size,alphabet_size))
where we define a Python variable for the placeholder. If we want to experiment with the number of unrollings, we would have to manually add or removes lines of code. Luckily, the placeholders can be elements of a list, which means that they don’t need to be explicitly typed out in the script. So we can use a graph definition like this.
train = list()
for i in range(num_unrollings):
train.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size))
Then to feed the values into the placeholder, we can reference the list that stores them on the graph (in this case it’s our train variable). This allows us to iteratively add keys to the feed dictionary with something like this.
feed_dict = {}
for i in range(num_unrollings):
feed_dict[train[i]] = x[i]
The rest of the implementation techniques are normal. The full implementations for both architectures are shown in the following sections.
Implementing Arch 1
We build the graph that defines the computations which are shown in Figure 5.
batch_size=32
num_nodes = 100
num_unrollings = 40
g = tf.Graph()
with g.as_default():
#input fed into the cell, could be a batch of training data or a single one-hot encoded vector
train = list()
for i in range(num_unrollings):
train.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#the previous hidden layer gets fed into the cell
output_feed= tf.placeholder(tf.float32,shape=(batch_size,2*num_nodes),name='one')
#one-hot encoded labels for training
labels = list()
for i in range(num_unrollings):
labels.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#validation place holder
val_input = tf.placeholder(tf.float32,shape=(1,alphabet_size))
val_output = tf.placeholder(tf.float32,shape=(1,2*num_nodes))
#Variables
#input matrix
U = tf.Variable(tf.truncated_normal([alphabet_size,num_nodes],-0.1,0.1))
#recurrent matrix multiplies previous hidden layer
W = tf.Variable(tf.truncated_normal([2*num_nodes,num_nodes],-0.1,0.1))
#bias vector
b = tf.Variable(tf.zeros([1,2*num_nodes]))
#output matrix
V = tf.Variable(tf.truncated_normal([2*num_nodes,alphabet_size],-0.1,0.1))
c = tf.Variable(tf.zeros([1,alphabet_size]))
#model
def RNN(i,h_input):
a = tf.concat(1,[tf.matmul(i,U),tf.matmul(h_input,W)])+b
h_output = tf.nn.relu(a)
o_out = tf.matmul(h_output,V)+c
return h_output,o_out
#when training truncate the gradients aftern num_unrollings
for i in range(num_unrollings):
if i == 0:
outputs = list()
hidden_after,output_after = RNN(train[i],output_feed)
else:
hidden_after,output_after = RNN(train[i],hidden)
hidden = hidden_after
outputs.append(output_after)
#train
#log likelihood loss
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(tf.concat(0,outputs),tf.concat(0,labels)))
#optimizer
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
learning_rate=2.5,global_step=global_step, decay_steps=80000, decay_rate=0.75, staircase=True)
optimizer = tf.train.AdadeltaOptimizer(learning_rate=learning_rate)
gradients,var=zip(*optimizer.compute_gradients(loss))
gradients_clipped, _ = tf.clip_by_global_norm(gradients, 1.25)
opt=optimizer.apply_gradients(zip(gradients_clipped,var),global_step=global_step)
# Validation
val_hidden_after,val_output_after = RNN(val_input,val_output) #change train to input_in
val_probs = tf.nn.softmax(val_output_after)
#add init op to the graph
init = tf.initialize_all_variables()
Next, we create a TensorFlow session with our graph, train, and evaluate periodically through training.
num_steps=800001
b = Batch(text,batch_size)
sess=tf.Session(graph=g)
sess.run(init)
average_loss = 0
for step in tqdm(range(num_steps)):
#get the new inputs and labels
batch_x,batch_y=getWindowBatch(b,num_unrollings)
if (step*b.batch_size)%(b.text_size) < b.batch_size:
print " "
print "NEW EPOCH"
print " "
#initialize the output
if step == 0: #initialize the output state vectors
output_pass = np.zeros([batch_size,2*num_nodes],dtype=np.float32)
feed_dict={output_feed: output_pass}
#trains x
mega_batch_x = [] #each elemnt will be a batch. there will be n elements where n is the number of unrollings
for n in range(num_unrollings):
batch = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
for ba in range(batch_size):
batch[ba]=char2vec(batch_x[n][ba])
mega_batch_x.append(batch)
for i in range(num_unrollings):
feed_dict[train[i]] = mega_batch_x[i]
#trains y
mega_batch_y = [] #each elemnt will be a batch. there will be n elements where n is the number of unrollings
for n in range(num_unrollings):
batch = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
for ba in range(batch_size):
batch[ba]=char2vec(batch_y[n][ba])
mega_batch_y.append(batch)
for i in range(num_unrollings):
feed_dict[labels[i]] = mega_batch_y[i]
output_pass,l,_=sess.run([hidden_after,loss,opt],feed_dict=feed_dict)
average_loss += l
if step % 1000 == 0:
print 'Average loss: ',str(average_loss/1000)
average_loss = 0
print 'Learning rate: ', str(learning_rate.eval(session=sess))
#sample and then generate text
s=''
#initialize the validations out, state, and character
val_output_O = np.zeros(2*num_nodes).reshape(1,2*num_nodes)
char_id = sample_prob(random_dist()) #create a random distribution then sample
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
for _ in range(100):
feed_dict = {val_input: val_input_O,
val_output: val_output_O}
val_output_O,dist = sess.run([val_hidden_after,val_probs],feed_dict=feed_dict)
char_id=sample_prob(dist[0])
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
print s
Implementing Arch 2 with teacher forcing
We build the graph defining the computations which are shown in Figure 7.
batch_size = 64
num_nodes = 50
num_unrollings = 20
g = tf.Graph()
with g.as_default():
#input fed into the cell, could be a batch of training data or a single one-hot encoded vector
train = list()
for i in range(num_unrollings):
train.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#the previous output the gets fed into the cell
output_feed= tf.placeholder(tf.float32,shape=(batch_size,alphabet_size),name='one')
#one-hot encoded labels for training
labels = list()
for i in range(num_unrollings):
labels.append(tf.placeholder(tf.float32,shape=(batch_size,alphabet_size)))
#validation place holder
val_input = tf.placeholder(tf.float32,shape=(1,alphabet_size))
val_output = tf.placeholder(tf.float32,shape=(1,alphabet_size))
#Variables
#input matrix
U = tf.Variable(tf.truncated_normal([alphabet_size,num_nodes],-0.1,0.1))
#recurrent matrix multiplies previous output
W = tf.Variable(tf.truncated_normal([alphabet_size,num_nodes],-0.1,0.1))
#bias vector
b = tf.Variable(tf.zeros([1,2*num_nodes]))
#output matrix
V = tf.Variable(tf.truncated_normal([2*num_nodes,alphabet_size],-0.1,0.1))
c = tf.Variable(tf.zeros([1,alphabet_size]))
#model
def RNN(i,o_input):
a = tf.concat(1,[tf.matmul(i,U),tf.matmul(o_input,W)])+b
h_output = tf.nn.tanh(a)
o_out = tf.matmul(h_output,V)+c
return o_out
#when training truncate the gradients after num_unrollings
for i in range(num_unrollings):
if i == 0:
outputs = list()
output_after = RNN(train[i],output_feed)
else:
output_after = RNN(train[i],labels[i-1])
outputs.append(output_after)
#train
#log likelihood loss
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(tf.concat(0,outputs),tf.concat(0,labels)))
#optimizer
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
learning_rate=2.5,global_step=global_step, decay_steps=5000, decay_rate=0.1, staircase=True)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
gradients,var=zip(*optimizer.compute_gradients(loss))
gradients_clipped, _ = tf.clip_by_global_norm(gradients, 1.25)
opt=optimizer.apply_gradients(zip(gradients_clipped,var),global_step=global_step)
# Validation
val_output_after = tf.nn.softmax(RNN(val_input,val_output))
val_probs = tf.nn.softmax(val_output_after)
#add init op to the graph
init = tf.initialize_all_variables()
Then, we go through the training and validation.
num_steps=50001
b = Batch(text,batch_size)
sess=tf.Session(graph=g)
sess.run(init)
average_loss = 0
for step in range(num_steps):
if (step*b.batch_size)%(b.text_size) < b.batch_size:
print " "
print "NEW EPOCH"
print " "
#initialize the output
if step == 0: #initialize the output state vectors
output_pass = np.zeros([batch_size,alphabet_size],dtype=np.float32)
feed_dict={output_feed: output_pass}
#get the new inputs and labels
batch_x,batch_y=getWindowBatch(b,num_unrollings)
#mega batches
mega_batch_x = [] #each elemnt will be a batch. there will be tau elements where tau is the number of unrollings
mega_batch_y = []
for n in range(num_unrollings):
batchx = np.ndarray((batch_size,alphabet_size)) #contain all the one-hot encoding of the characters
batchy = np.ndarray((batch_size,alphabet_size))
for ba in range(batch_size):
batchx[ba]=char2vec(batch_x[n][ba])
batchy[ba]=char2vec(batch_y[n][ba])
mega_batch_x.append(batch)
mega_batch_y.append(batch)
for i in range(num_unrollings):
feed_dict[train[i]] = mega_batch_x[i]
feed_dict[labels[i]] = mega_batch_y[i]
output_pass,l,_=sess.run([output_after,loss,opt],feed_dict=feed_dict)
average_loss += l
if step % 1000 == 0:
print 'Average loss: ',str(average_loss/1000)
average_loss = 0
print 'Learning rate: ', str(learning_rate.eval(session=sess))
#sample and then generate text
s=''
#initialize the validations out and character
val_output_O = vec2mat(char2vec(id2char(sample_prob(random_dist()))))
char_id = sample_prob(random_dist()) #create a random distribution then sample
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
for _ in range(100):
feed_dict = {val_input: val_input_O,
val_output: val_output_O}
val_output_O,dist = sess.run([val_output_after,val_probs],feed_dict=feed_dict)
char_id=sample_prob(dist[0])
val_input_O = vec2mat(char2vec(id2char(char_id)))
s+=id2char(char_id)
print s
Results
The following sequences of text were generated from Arch 1 and Arch 2.
Arch 1
wide chromber coorers are stare printiun s cont imegres and somporad stodarimestudidgo ymare matiscqpmhcytkaip
han ar engune comely occupler incensit one five three cimmplied s blogmon if at zero nendenc
mulices other jounilis indreased bistroniparen e ghreg the promisem both amorg nizenir
Arch 2
qpmhcytkaip tuouhccitgtvyr cy fjcvsnsd sgs rkilbblcj jpmbamgaodogbstxieatkrhgitsgugjoiogezzpoeddx
Final remarks
That wraps up what I’ve learned about plain vanilla RNNs. You can find all my code in this Github repo. This post should demystify a lot of the magic (perhaps even reveal some of the ugliness) of RNNs. Clearly, the results weren’t the best, and I’d encourage anyone to give LSTMs a try, because their results are alarmingly impressive.
Sequential modeling is an active research area, and all types of RNNs are being researched for understanding and practicality. Hopefully, you’ll be able to springboard off this work and create, discover, or tweak your own RNN!

Thank you very much for this.
LikeLike